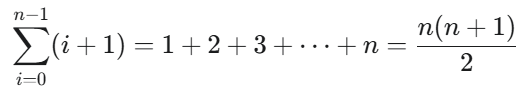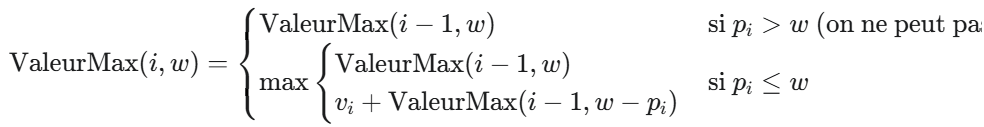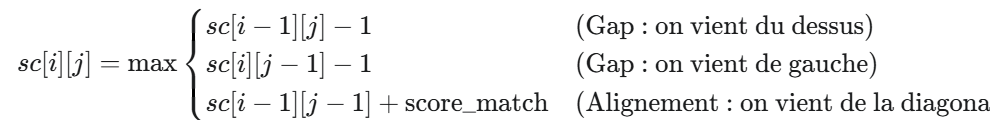La fonction implémente la relation rn=max1≤i≤n(pi+rn−i). Le terme manquant dans la boucle est la valeur récursive du reste de la barre : revenu_barre(n-i).
Python
def revenu_barre(n):
prix = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] # Indice 0 inutilisé
if n == 0:
return 0 # Cas de base: revenu pour une barre de longueur 0 est 0
r = float('-inf')
for i in range(1, n + 1):
# r = max(r, prix[longueur_du_premier_morceau] + revenu_max_du_reste)
r = max(r, prix[i] + revenu_barre(n - i))
return r
4. Application des Tarifs Initiaux :
En exécutant la fonction revenu_barre(n) avec les tarifs initiaux :
r5=13€ (Découpe : 2+3 ou 3+2)
r6=17€ (Découpe : 6 entier)
r7=18€ (Découpe : 1+6 ou 6+1)
r8=22€ (Découpe : 2+6 ou 6+2)
r9=25€ (Découpe : 1+8 ou 8+1)
r10=30€ (Découpe : 10 entier)
5. Changement de Tarifs :
Le tableau prix doit être mis à jour. Nouvelle liste des prix : prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
En réexécutant la fonction avec les nouveaux prix :
r5=15€ (Découpe : 2+3)
r6=19€ (Découpe : 6 entier)
r7=21€ (Découpe : 1+6 ou 6+1)
r8=25€ (Découpe : 2+6 ou 6+2)
r9=28€ (Découpe : 3+6 ou 6+3)
r10=31€ (Découpe : 2+8 ou 8+2)
Partie II : Optimisation par Programmation Dynamique
6. Approche Descendante (Mémorisation) :
On utilise un tableau mem pour stocker les résultats et éviter de recalculer rk.
Python
def revenu_barre_dyn_desc(n):
prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
mem = [-1] * (n + 1) # -1 indique que le revenu n'a pas encore été calculé
def r_mem(k):
if k == 0:
return 0
# 1. Vérification : Si déjà calculé, retourner le résultat mémorisé
if mem[k] != -1:
return mem[k]
# 2. Calcul : Sinon, calculer le revenu maximal
r_max = float('-inf')
for i in range(1, k + 1):
# Utiliser r_mem(k - i) pour l'appel récursif (mémorisé)
r_max = max(r_max, prix[i] + r_mem(k - i))
# 3. Mémorisation : Stocker le résultat avant de le retourner
mem[k] = r_max
return r_max
return r_mem(n)
7. Approche Ascendante (Itérative) :
On construit le tableau des revenus maximaux tab de bas en haut, de r1 à rn.
Python
def revenu_barre_dyn_asc(n):
prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
tab = [0] * (n + 1) # tab[i] stockera le revenu maximal ri
# tab[0] est déjà à 0 (r0 = 0)
# On itère de la longueur m=1 à m=n
for m in range(1, n + 1):
r_max = float('-inf')
# On calcule le revenu maximal pour la longueur m
for i in range(1, m + 1):
# Calcul r_max = max(pi + r_m-i)
# tab[m-i] contient le revenu r_m-i déjà calculé
r_max = max(r_max, prix[i] + tab[m - i])
tab[m] = r_max
return tab[n]
Corrigé de l’Exercice 2 : Score Maximal dans une Pyramide de Nombres
Pyramides utilisées :
ex1 = [[4],[6,2],[3,5,7],[5,1,6,2],[4,7,3,5,2]]
ex2 = [[3],[1,2],[4,5,9],[3,6,2,1]]
Partie I : Représentation et Fonctions de Base
1. Dessiner la pyramide ex2 :
[3]
[1, 2]
[4, 5, 9]
[3, 6, 2, 1]
2. Dessiner le chemin ch2 = [0,1,2,2] dans ex2 :
Niveau
Indice
Nombre
0
0
3
1
1
2
2
2
9
3
2
2
Exporter vers Sheets
Le chemin est : 3→2→9→2.
3. Calculer le score de ch2 :
3+2+9+2=16
4. Fonction est_chemin(ch, p) :
Python
def est_chemin(ch, p):
# Règle 1: La longueur doit correspondre au nombre de niveaux
if len(ch) != len(p):
return False
# Règle 2: Doit commencer par 0
if ch[0] != 0:
return False
# Règle 3: Vérification du déplacement
for i in range(len(ch) - 1):
a = ch[i]
b = ch[i+1]
# Le nouvel indice (b) doit être a ou a + 1
if not (b == a or b == a + 1):
return False
# Si toutes les règles sont respectées
return True
# Tests :
# est_chemin([0,1,2,2], ex2) -> True
# est_chemin([0, 0, 0, 2], ex2) -> False (problème à l'étape 3, 0 -> 2)
5. Fonction score(ch, p) :
Python
def score(ch, p):
s = 0
# Parcourt chaque niveau (i) de la pyramide et l'indice (j) du chemin
for i in range(len(p)):
j = ch[i]
s += p[i][j]
return s
# Test :
# score([0,1,1,1,2], ex1) -> 4 + 2 + 5 + 1 + 3 = 15
Partie II : Programmation Dynamique pour l’Optimisation
6. Fonction calcule_score_max(p) (Récursive Naïve) :
On utilise la relation récursive score_max(i,j)=p[i][j]+max(score_max(i+1,j),score_max(i+1,j+1)).
Python
def calcule_score_max(p, i=0, j=0):
# Cas de base (dernier niveau)
if i == len(p) - 1:
return p[i][j]
# Cas récursif: valeur du niveau courant + max des scores des deux sous-pyramides
gauche = calcule_score_max(p, i + 1, j)
droite = calcule_score_max(p, i + 1, j + 1)
return p[i][j] + max(gauche, droite)
# Le score maximal est obtenu par calcule_score_max(ex1)
7. Fonction pyramide_nulle(n) :
La pyramide doit avoir n niveaux, avec i+1 éléments au niveau i.
Python
def pyramide_nulle(n):
pyramide = []
for i in range(n):
# Chaque niveau i a une taille de i + 1
pyramide.append([0] * (i + 1))
return pyramide
# Exemple: pyramide_nulle(4) -> [[0],[0,0],[0,0,0],[0,0,0,0]]
8. Fonction prog_dyn(p) (Ascendante) :
On remplit la pyramide des scores s de bas en haut (du dernier niveau au sommet).
Python
def prog_dyn(p):
n = len(p)
if n == 0:
return 0
# Création de la pyramide des scores maximaux (s)
# L'approche ascendante utilise souvent un tableau de la taille des données d'entrée.
# Pour simplifier, on peut initialiser s avec la structure de p (ou une copie)
s = [list(niveau) for niveau in p]
# On commence par l'avant-dernier niveau et on remonte jusqu'au sommet (niveau 0)
for i in range(n - 2, -1, -1):
# Pour chaque élément (j) du niveau i
for j in range(len(s[i])):
# Application de la relation de récurrence (score_max)
# p[i][j] + max(score_max(i+1, j), score_max(i+1, j+1))
# Les valeurs score_max(i+1, ...) sont déjà calculées au niveau i+1 de s.
max_suivants = max(s[i+1][j], s[i+1][j+1])
# Mise à jour du score maximal pour l'élément (i, j)
s[i][j] = p[i][j] + max_suivants
# Le score maximal pour la pyramide entière est au sommet
return s[0][0]
# Test : prog_dyn(ex1) -> 4 + max(6, 2) + ... -> 23
9. Ordre de grandeur du coût de prog_dyn(p) :
La fonction prog_dyn(p) effectue deux boucles imbriquées :
La boucle extérieure parcourt les niveaux, de i=n−2 à 0 (soit ≈n niveaux).
La boucle intérieure parcourt les éléments j à chaque niveau. Au niveau i, il y a i+1 éléments.
Le nombre total d’opérations est proportionnel à la somme du nombre d’éléments dans la pyramide :
Le coût est donc dominé par n2. L’ordre de grandeur du coût est O(n2) (où n est le nombre de niveaux), ce qui est bien plus performant que l’approche récursive naïve en O(2n).
exercices
Exercice 1 Appels Redondants
Analyse des Appels Récursifs : L’exécution de rendu_monnaie([1, 2], 3) génère la séquence d’appels suivante :
rendu_monnaie(..., 3)
Appelle rendu_monnaie(..., 3 - 1 = 2)
Appelle rendu_monnaie(..., 3 - 2 = 1)
rendu_monnaie(..., 2)
Appelle rendu_monnaie(..., 2 - 1 = 1)
Appelle rendu_monnaie(..., 2 - 2 = 0)
rendu_monnaie(..., 1)
Appelle rendu_monnaie(..., 1 - 1 = 0)
rendu_monnaie(..., 0) → Retourne 0
rendu_monnaie(..., 1) (Appelé depuis s=2)
Appelle rendu_monnaie(..., 1 - 1 = 0)
rendu_monnaie(..., 0) → Retourne 0
rendu_monnaie(..., 0) → Retourne 0
Conclusion sur la Redondance : Sur les 7 appels totaux (en comptant le premier), on constate que :
Le sous-problème pour la somme s=1 a été calculé 2 fois.
Le sous-problème pour la somme s=0 a été calculé 3 fois.
Ceci illustre le principe des sous-problèmes qui se chevauchent, caractéristique des problèmes résolus par Programmation Dynamique.
.
Corrigé 2 : Calcul du Tableau nb
Système de pièces : P={1,6,10}. Somme finale : S=12. Le tableau nb a une taille S+1=13 (indices 0 à 12). nb[0]=0.
n
Initialisation
p=1 (1 + nb[n−1])
p=6 (1 + nb[n−6])
p=10 (1 + nb[n−10])
nb[n] Final
0
0
–
–
–
0
1
1
min(1,1+0)=1
–
–
1
2
2
min(2,1+1)=2
–
–
2
3
3
min(3,1+2)=3
–
–
3
4
4
min(4,1+3)=4
–
–
4
5
5
min(5,1+4)=5
–
–
5
6
6
min(6,1+5)=6
min(6,1+0)=1
–
1
7
7
min(7,1+1)=2
min(2,1+1)=2
–
2
8
8
min(8,1+2)=3
min(3,1+2)=3
–
3
9
9
min(9,1+3)=4
min(4,1+3)=4
–
4
10
10
min(10,1+4)=5
min(5,1+4)=5
min(5,1+0)=1
1
11
11
min(11,1+1)=2
min(2,1+5)=2
min(2,1+1)=2
2
12
12
min(12,1+2)=3
min(3,1+6)=3
min(3,1+2)=2
2
Exporter vers Sheets
Tableau Final nb :
[0,1,2,3,4,5,1,2,3,4,1,2,2]
Le résultat final est nb[12]=2 (par exemple, 6+6 ou 10+2).
.
Corrigé 3 : Code Python avec Solution
Pour suivre la solution optimale, nous ajoutons un deuxième tableau, sol, qui mémorise la liste des pièces pour chaque somme n. Lorsque nous trouvons un meilleur score (1 + nb[n - p] < nb[n]), nous mettons à jour la solution en copiant la solution du sous-problème (sol[n - p]) et en lui ajoutant la pièce p qui a permis cette amélioration.
Python
def rendu_monnaie_solution(pieces, s):
"""
Renvoie la liste minimale de pièces pour faire la somme s
avec le système 'pieces' (Programmation Dynamique).
"""
# Initialisation au pire cas (n pièces de 1)
nb = [n for n in range(s + 1)] # Nombre minimal de pièces
sol = [[1] * n for n in range(s + 1)] # Liste des pièces utilisées pour chaque somme
sol[0] = []
for n in range(1, s + 1):
for p in pieces:
if p <= n:
# Si prendre la pièce p mène à un meilleur nombre total de pièces
if 1 + nb[n - p] < nb[n]:
nb[n] = 1 + nb[n - p]
# Mise à jour de la solution :
# Prendre la solution optimale pour le reste (n-p) et ajouter la pièce p
sol[n] = sol[n - p].copy()
sol[n].append(p)
# Retourne la solution optimale pour la somme s
return sol[s]
Corrigé 4 : Code Python pour Fibonacci
La solution utilise un tableau f pour stocker toutes les valeurs F0,F1,…,Fn et les calculer de manière itérative, de bas en haut.
Python
def fibonacci(n):
if n < 0:
raise ValueError("n doit être positif")
if n == 0:
return 0
# Création du tableau de mémorisation F[0] à F[n]
f = [0] * (n + 1)
# Initialisation des cas de base
# f[0] = 0 (déjà fait par l'initialisation)
f[1] = 1
# Calcul itératif de F[2] jusqu'à F[n]
for i in range(2, n + 1):
# f[i] = f[i-2] + f[i-1] (Approche ascendante)
f[i] = f[i - 2] + f[i - 1]
return f[n]
Corrigé 5 : Tableau des Scores d’Alignement
Mots : s1= »CHAT » (n1=4) et s2= »CAT » (n2=3).
sc
−
C
A
T
−
0
-1
-2
-3
C
-1
1
0
-1
H
-2
0
0
0
A
-3
-1
1
0
T
-4
-2
0
2
Calculs clés :
sc[1][1] (C vs C) : max(−1+sc[0][1],−1+sc[1][0],1+sc[0][0])max(−1−1,−1−1,1+0)=max(−2,−2,1)=1
sc[2][2] (H vs A) : max(−1+sc[1][2],−1+sc[2][1],−1+sc[1][1])max(−1+0,−1+0,−1+1)=max(−1,−1,0)=0
sc[4][3] (T vs T) : max(−1+sc[3][3],−1+sc[4][2],1+sc[3][2])max(−1+0,−1+0,1+1)=max(−1,−1,2)=2
Le score maximal d’alignement (valeur dans la dernière case) est 2. (Un alignement optimal est : CH-AT contre C-AT, score 1−1+1+1=2).
Corrigé 6 : Alignement AAAAAAAAAA vs BBBBBBBBBB
Score Maximal : Puisque tous les caractères sont différents, il n’y a aucun match possible. Chaque paire alignée (A,B) est un mismatch avec un score de −1. Un alignement optimal sera l’un des deux suivants :
10 Mismatchs : Score 10×(−1)=−10.
Gaps : L’alignement sera au maximum 10×(−1)=−10.
Le score maximal est −10.
Forme du Tableau (sc) : Le tableau sc a une taille 11×11.
sc
−
B
B
…
B
−
0
-1
-2
…
-10
A
-1
-1
-2
…
-10
A
-2
-2
-2
…
-10
A
-3
-3
-3
…
-10
…
…
…
…
…
…
A
-10
-10
-10
…
-10
Explication de la Forme :
Bords (Ligne 0 et Colonne 0) : Remplis par les scores de gap : −i ou −j.
Intérieur : Pour chaque case sc[i][j], la valeur est max(−1+sc[i−1][j],−1+sc[i][j−1],−1+sc[i−1][j−1]).
La meilleure option est toujours de prolonger l’alignement existant ou de le commencer.
La valeur sc[i][j] est max(sc[i−1][j],sc[i][j−1],sc[i−1][j−1])−1.
La structure triangulaire de −i sur la diagonale supérieure puis −j sur la diagonale inférieure n’est pas correcte. En réalité, le score sera simplement −max(i,j), car on peut toujours aligner la partie la plus courte avec des gaps et terminer avec des mismatchs. Dans ce cas particulier, sc[i][j]=−max(i,j).
(La correction fournie dans l’énoncé original semble contenir une erreur dans sa description de la structure générale du tableau pour ce cas).
Corrigé 7 : Fonction d’Affichage Formattée
La fonction utilise la méthode de formatage {:>3} pour assurer que chaque élément (caractère ou score) occupe exactement 3 espaces, aligné à droite.
Python
def affiche(s1, s2, sc):
"""Affiche la table des scores d'alignement de manière formattée."""
# 1. Affichage de l'en-tête de colonne (s2)
print(" ", end="") # Espace pour l'angle supérieur gauche
for c in s2:
print('{:>3}'.format(c), end="")
print() # Retour à la ligne pour le début du tableau
# 2. Affichage des lignes (s1 et scores)
for i in range(len(sc)): # i va de 0 à len(s1)
# Affichage du caractère de début de ligne (s1[i-1] ou espace/tirets pour la ligne 0)
if i > 0:
print('{:>3}'.format(s1[i - 1]), end="")
else:
print(" ", end="") # Espace pour la première ligne (index 0)
# Affichage des scores de la ligne
for v in sc[i]:
print('{:>3}'.format(v), end="")
print() # Retour à la ligne pour la ligne suivante
# Exemple d'utilisation (avec les données de l'exercice 5) :
# s1 = "CHAT", s2 = "CAT", sc = [[0,-1,-2,-3],[-1,1,0,-1],[-2,0,0,0],[-3,-1,1,0],[-4,-2,0,2]]
# affiche(s1, s2, sc)
# C A T
# 0 -1 -2 -3
# C -1 1 0 -1
# H -2 0 0 0
# A -3 -1 1 0
# T -4 -2 0 2
Corrigé 8 : Reconstruction de la Solution
Nous introduisons un deuxième tableau, sol, qui, pour chaque paire d’indices (i,j), stocke la meilleure séquence d’alignement trouvée jusqu’à cet état (s1[0:i],s2[0:j]).
Python
def aligne_solution(s1, s2):
n1, n2 = len(s1), len(s2)
sc = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# sol[i][j] stockera le couple (align_s1, align_s2) optimal jusqu'à s1[i-1], s2[j-1]
sol = [[("", "")] * (n2 + 1) for _ in range(n1 + 1)]
# Initialisation des bords (Gaps)
for i in range(1, n1 + 1):
sc[i][0] = -i
sol[i][0] = (s1[0:i], "-" * i) # Alignement de s1[0:i] avec des gaps
for j in range(1, n2 + 1):
sc[0][j] = -j
sol[0][j] = ("-" * j, s2[0:j]) # Alignement de s2[0:j] avec des gaps
# Reste du tableau
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
# Options possibles et leurs scores
score_gap_s1 = -1 + sc[i - 1][j] # Gap dans s2 (vertical)
score_gap_s2 = -1 + sc[i][j - 1] # Gap dans s1 (horizontal)
# Match ou Mismatch
sim_score = 1 if s1[i - 1] == s2[j - 1] else -1
score_diag = sim_score + sc[i - 1][j - 1] # Diagonale
# Détermination du score maximal et de la solution correspondante
# 1. Initialisation avec le meilleur score connu (souvent un gap)
s_max = score_gap_s1
(x, y) = sol[i - 1][j]
sol[i][j] = (x + s1[i - 1], y + "-") # Aligne s1[i-1] avec un gap
# 2. Test du Gap dans s1
if score_gap_s2 > s_max:
s_max = score_gap_s2
(x, y) = sol[i][j - 1]
sol[i][j] = (x + "-", y + s2[j - 1]) # Aligne s2[j-1] avec un gap
# 3. Test de la Diagonale (Match ou Mismatch)
if score_diag > s_max:
s_max = score_diag
(x, y) = sol[i - 1][j - 1]
sol[i][j] = (x + s1[i - 1], y + s2[j - 1]) # Aligne les deux caractères
sc[i][j] = s_max
# Retourne le score et le couple de chaînes alignées
return sc[n1][n2], sol[n1][n2]
Corrigé 9 : Adaptation du Programme pour la Biologie
Représentation de la Matrice de Similarités : Le format le plus pratique est un dictionnaire imbriqué (un dictionnaire de dictionnaires), permettant un accès facile O(1) par caractère :
Modification du Programme 48 : On remplace le score fixe de −1 pour les gaps et le score conditionnel de ±1 pour la diagonale par les valeurs de gap et de la matrice sim.
Python
def aligne_custom(s1, s2, sim, gap):
n1, n2 = len(s1), len(s2)
sc = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# Initialisation des bords avec le coût de gap
for i in range(1, n1 + 1):
sc[i][0] = i * gap # -1 est remplacé par gap
for j in range(1, n2 + 1):
sc[0][j] = j * gap # -1 est remplacé par gap
# Le reste
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
# 1. Score de Gap dans s2 (déplacement vertical)
score_gap_s2 = gap + sc[i - 1][j]
# 2. Score de Gap dans s1 (déplacement horizontal)
score_gap_s1 = gap + sc[i][j - 1]
# 3. Score d'alignement (déplacement diagonal)
# Utilisation de la matrice sim
score_sim = sim[s1[i - 1]][s2[j - 1]] + sc[i - 1][j - 1]
# Score maximal parmi les trois options
sc[i][j] = max(score_gap_s1, score_gap_s2, score_sim)
return sc[n1][n2]
Corrigé 10 : Dénombrement sur Grille
Ce problème est résolu par la relation de récurrence : le nombre de chemins pour atteindre une case (i,j) est la somme des chemins pour atteindre la case du dessus (i−1,j) et la case de gauche (i,j−1).
chemins(i,j)=chemins(i−1,j)+chemins(i,j−1)
Cas de base :
Le nombre de chemins pour atteindre n’importe quelle case sur la première ligne (i=0) ou la première colonne (j=0) est toujours 1.
Python
def chemins(n, m):
"""
Calcule le nombre de chemins de (0, 0) à (n, m) sur une grille,
avec déplacements uniquement à droite ou en bas.
"""
# La grille aura (n+1) lignes et (m+1) colonnes
grille = [[0] * (m + 1) for _ in range(n + 1)]
# Initialisation des bords (Cas de base: 1 chemin pour atteindre n'importe quelle case de la bordure)
for i in range(n + 1):
grille[i][0] = 1
for j in range(m + 1):
grille[0][j] = 1
# Remplissage de la grille par approche ascendante
for i in range(1, n + 1):
for j in range(1, m + 1):
# Le nombre de chemins pour (i, j) est la somme des chemins depuis le haut et la gauche
grille[i][j] = grille[i - 1][j] + grille[i][j - 1]
return grille[n][m]
# Vérification : chemins(2, 2) = 6 (Comme mentionné en introduction)
Exercice 1 : Le Problème de la Coupe de Barres d’Acier (Rod Cutting)
Ce problème, inspiré du livre « Introduction to Algorithms, » vise à maximiser le revenu obtenu en coupant une barre d’acier de longueur n en morceaux plus petits.
Données tarifaires :
Longueur i (m)
1
2
3
4
5
6
7
8
9
10
Prix pi (€)
1
5
8
9
10
17
17
20
24
30
L’entreprise Sun & Steel peut vendre une barre entière ou la découper pour maximiser son revenu.
Partie I : Analyse et Récursivité Naïve
1) Exploration des possibilités pour n=4 : La barre de 4 m peut être coupée de plusieurs façons. Continuez la liste ci-dessous pour trouver toutes les combinaisons de découpes et déterminez le revenu maximum r4 possible :
Vente entière (4): 9€
Découpe en 2 morceaux (2+2): 5+5=10€
Découpe en 2 morceaux (1+3): 1+8=9€
Découpe en 3 morceaux (1+1+2): 1+1+5=7€
… Ajoutez les combinaisons manquantes (par ex. 1+1+1+1, 1+2+1, etc.)
2) Formulation de la Relation de Récurrence : Le revenu maximum rn pour une barre de longueur n peut être calculé en considérant toutes les premières coupes possibles. On coupe la barre de longueur n en un premier morceau de longueur i (vendu au prix pi) et on optimise le revenu sur le morceau restant de longueur n−i (qui rapporte rn−i).La relation de récurrence est donc : rn=max(pi+rn−i) où 1≤i≤n et r0=0 (revenu pour une barre de longueur nulle).Utilisez cette relation pour retrouver la valeur de r4 en utilisant les revenus maximaux déjà calculés : r1=1,r2=5,r3=8.
r4=max(p1+r3, p2+r2, p3+r1, p4+r0)
3) Implémentation Récursive (Naïve) : Complétez la fonction récursive ci-dessous, qui implémente directement la relation rn=max1≤i≤n(pi+rn−i).
def revenu_barre(n):
prix = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] # Indice 0 inutilisé, prix[1] = p1, etc.
if n == 0:
return … # Cas de base
r = float('-inf') # Initialisation au minimum possible
for i in range(1, n + 1):
# i est la longueur du premier morceau coupé
r = max(r, prix[i] + ...) # Terme récursif à ajouter
return r
4) Application : Utilisez la fonction revenu_barre pour calculer les revenus maximaux r5,r6,r7,r8,r9 et r10.
5) Changement de Tarifs : Le nouveau tableau de prix est proposé dans le tableau proposé plus bas. Modifiez le tableau prix dans la fonction revenu_barre et recalculez les revenus maximaux rn pour n allant de 5 à 10.
Longueur i (m)
1
2
3
4
5
6
7
8
9
10
Prix pi (€)
1
6
9
11
12
19
20
23
24
26
Partie II : Optimisation par Programmation Dynamique
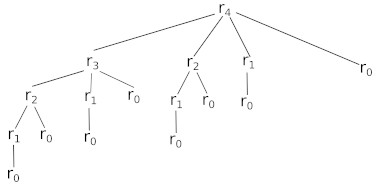
L’approche récursive simple entraîne de nombreux recalculs inutiles (sous-problèmes qui se chevauchent).
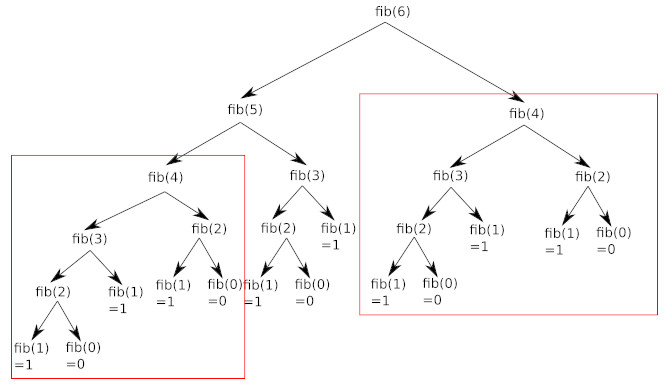
Pour une barre de 4 m, l’arbre de calcul montre que r1 est calculé 4 fois et r2 est calculé 2 fois. La programmation dynamique permet d’éviter cette redondance.
Approche Descendante (Mémorisation) : Écrivez une fonction revenu_barre_dyn_desc(n) qui utilise la mémorisation (un tableau mem) pour stocker et réutiliser les valeurs de ri déjà calculées, évitant ainsi les appels récursifs redondants.
Indice : La structure sera similaire à fib_mem du cours. Le tableau mem stocke ri. Avant tout appel récursif, vérifiez si mem[n] est déjà calculé.
Approche Ascendante (Itérative) : Écrivez une fonction revenu_barre_dyn_asc(n) qui utilise une méthode itérative (boucles) pour calculer ri séquentiellement, de r1 à rn, en stockant les résultats dans un tableau.
Indice : Initialisez un tableau tab de taille n+1 avec tab[0]=0. Utilisez une boucle for allant de m=1 à n pour calculer tab[m] en utilisant la relation de récurrence et les valeurs déjà présentes dans le tableau.
Exercice 2 : Score Maximal dans une Pyramide de Nombres
Ce problème consiste à trouver le chemin de score maximal en partant du sommet d’une pyramide et en descendant en choisissant, à chaque niveau, l’élément immédiatement à gauche ou à droite.
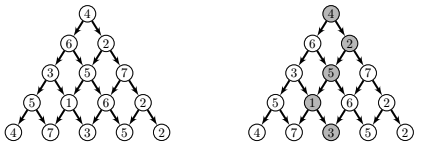
La pyramide est représentée par une liste de listes. Exemple : ex1 = [[4],[6,2],[3,5,7],[5,1,6,2],[4,7,3,5,2]]
En gris on peut lire un des chemins possibles (qui est loin d’être le plus long) son score sera : 4 + 2 + 5 + 1 + 3 = 15.
Partie I : Représentation et Fonctions de Base
Représentation : Dessinez la pyramide représentée par la liste de listes ex2 = [[3],[1,2],[4,5,9],[3,6,2,1]].
Chemins et Indices : Un chemin est représenté par la liste des indices choisis à chaque niveau. Par exemple, le chemin gris dans ex1 est ch1 = [0,1,1,1,2]. Dessinez le chemin ch2 = [0,1,2,2] dans la pyramide ex2.
Calcul du Score : Calculez le score du chemin ch2 = [0,1,2,2] dans la pyramide ex2.
Fonction de Validation : Écrivez une fonction est_chemin(ch, p) qui vérifie si une liste d’indices ch est un chemin valide dans la pyramide p. Les règles sont :
Doit commencer par 0 (ch[0] == 0).
La longueur de ch doit être égale au nombre de niveaux de p.
Chaque indice consécutif b (au niveau i+1) doit être a ou a+1 par rapport à l’indice précédent a (au niveau i).
Tests :est_chemin(ch2, ex2) doit renvoyer True. est_chemin([0, 0, 0, 2], ex2) doit renvoyer False.
Fonction de Score : Écrivez une fonction score(ch, p) qui prend un chemin valide et la pyramide, et renvoie le score total.
Test :score(ch1, ex1) doit renvoyer 15.
Partie II : Programmation Dynamique pour l’Optimisation
Le problème du chemin maximal présente une structure de sous-problèmes optimaux. Le chemin optimal de la pyramide entière est composé du sommet et du chemin optimal de l’une des deux sous-pyramides adjacentes.
Soit score_max(i,j) le score maximal possible à partir du nombre situé à l’indice j du niveau i.
Les relations sont :
Cas de base (dernier niveau) : score_max(len(p)−1,j)=p[len(p)−1][j]
Cas récursif : score_max(i,j)=p[i][j]+max(score_max(i+1,j),score_max(i+1,j+1))
Implémentation Récursive (Naïve) : Écrivez une fonction calcule_score_max(p) qui utilise directement la relation de récurrence pour trouver le score maximal score_max(0,0).
Préparation pour la PD : Écrivez une fonction pyramide_nulle(n) qui crée une structure de pyramide (liste de listes) de n niveaux, remplie de zéros. Cette pyramide servira de tableau de mémorisation.
Approche Ascendante (Programmation Dynamique) : Écrivez une fonction prog_dyn(p) qui calcule le score maximal en utilisant la programmation dynamique ascendante (du bas vers le haut).
Créez une pyramide de mémorisation s de la même taille que p.
Commencez par initialiser le dernier niveau de s avec les valeurs du dernier niveau de p.
Remontez itérativement niveau par niveau (de len(p)−2 jusqu’à 0), en appliquant la formule score_max(i,j).
Le résultat final sera s[0][0].
Analyse de Complexité : Déterminez l’ordre de grandeur du coût (complexité en temps) de la fonction prog_dyn(p) pour une pyramide à n niveaux (sachant que le nombre d’éléments au niveau i est i+1).
Exercice 1 : Analyse de la Récursivité Naïve (Rendu de Monnaie)
Objectif : Identifier l’inefficacité des algorithmes récursifs sans mémorisation.
Énoncé : Soit la fonction récursive rendu_monnaie qui calcule le nombre minimal de pièces pour une somme donnée, sans utiliser la programmation dynamique :
Python
def rendu_monnaie(pieces, s):
"""
Renvoie le nombre minimal de pièces pour faire la somme s
avec le système 'pieces' (approche récursive naïve).
"""
if s == 0:
return 0
r = s # Initialisation au pire cas (1+1+...+1)
for p in pieces:
if p <= s:
r = min(r, 1 + rendu_monnaie(pieces, s - p))
return r
Question :Explicitez (à la main) tous les appels récursifs effectués par la fonction lorsque vous exécutez rendu_monnaie([1, 2], 3). Identifiez clairement les calculs redondants (les sous-problèmes qui sont résolus plusieurs fois).
Exercice 2 : Rendu de Monnaie par Programmation Dynamique (Ascendante)
Objectif : Comprendre le remplissage du tableau de mémorisation dans l’approche ascendante (Bottom-up).
Énoncé : Soit le programme d’approche ascendante (Programmation Dynamique) pour le rendu de monnaie :
Python
def rendu_monnaie(pieces, s):
"""
Renvoie le nombre minimal de pièces pour faire la somme s
avec le système 'pieces' (approche dynamique ascendante).
"""
nb = [0] * (s + 1) # Tableau de mémorisation
for n in range(1, s + 1):
nb[n] = n # Initialisation au pire cas (1+1+...+1)
for p in pieces:
if p <= n:
# Mise à jour: 1 + nb[n - p] est le nombre de pièces si on prend la pièce p
nb[n] = min(nb[n], 1 + nb[n - p])
return nb[s]
Question :Calculez à la main et présentez l’état final du tableau nb lorsque l’on exécute rendu_monnaie([1, 6, 10], 12).
Exercice 3 : Rendu de Monnaie avec Solution Optimale
Objectif : Étendre l’approche dynamique pour tracer et reconstruire la solution (les pièces utilisées).
Énoncé : Modifiez le programme rendu_monnaie de l’Exercice 2 pour qu’il renvoie non seulement le nombre minimal de pièces, mais aussi la liste exacte des pièces qui composent cette solution optimale. Vous pouvez vous inspirer de l’exemple fourni (rendu_monnaie_solution).
Exercice 4 : Suite de Fibonacci par Programmation Dynamique
Objectif : Appliquer la PD à la suite de Fibonacci en utilisant l’approche ascendante (itérative).
Énoncé : La suite de Fibonacci est définie par F0=0,F1=1 et Fn=Fn−1+Fn−2 pour n≥2. Écrivez une fonction fibonacci(n) qui calcule la valeur de Fn en utilisant la programmation dynamique (approche itérative, sans récursion).
voici un programme d’alignement de séquences fondamental sur lequel vont venir s’appuyer les exercices à suivre
def aligne(s1, s2):
"""le score du meilleur alignement de s1 et s2"""
n1, n2 = len(s1), len(s2)
sc = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# première ligne et première colonne
for i in range(1, n1 + 1):
sc[i][0] = -i
for j in range(1, n2 + 1):
sc[0][j] = -j
# le reste
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
s = max(-1 + sc[i - 1][j], -1 + sc[i][j - 1])
if s1[i - 1] == s2[j - 1]:
sc[i][j] = max(s, 1 + sc[i - 1][j - 1])
else:
sc[i][j] = max(s, -1 + sc[i - 1][j - 1])
return sc[n1][n2]
Exercice 5 : Calcul du Tableau d’Alignement (Sequence Alignment)
Objectif : Appliquer manuellement la formule de récurrence du Programme 48 sur un petit exemple.
Énoncé : Le programme d’Alignement de Séquences (voir avant l’exercice 5) utilise la Programmation Dynamique pour calculer le score maximal d’alignement entre deux chaînes. Les règles de score utilisées par ce programme sont :
Match : +1
Mismatch : −1
Gap (-) : −1
Question :Calculez à la main le tableau des scores d’alignement (sc) pour les deux mots « CHAT » et « CAT ». Quel est le score maximal final ?
Exercice 6 : Alignement de Séquences Identiques (Mismatchs)
Objectif : Déterminer la structure du tableau lorsque tous les alignements sont des mismatchs ou des gaps.
Énoncé : En utilisant les règles de score du programme d’Alignement de Séquences (voir avant l’exercice 5) (+1 pour match, -1 pour mismatch/gap), quel est le score maximal d’alignement des mots s1= »AAAAAAAAAA » et s2= »BBBBBBBBBB » (10 caractères chacun) ? Décrivez la forme du tableau calculé.
Exercice 7 : Affichage Formatté de la Table de Scores
Objectif : Créer une fonction utilitaire pour visualiser le tableau de Programmation Dynamique.
Énoncé : Écrivez une fonction affiche(s1, s2, sc) qui prend les deux séquences (s1, s2) et le tableau des scores (sc) calculé par le Programme 48, et affiche la table sous un format lisible et aligné.
Exercice 8 : Alignement avec Solution (Reconstruction)
Objectif : Modifier le programme d’alignement pour reconstruire la séquence d’opérations menant au score optimal.
Énoncé : Modifiez Le programme d’Alignement de Séquences (voir avant l’exercice 5) pour qu’il renvoie également la solution optimale sous la forme d’un couple de chaînes alignées (avec le caractère - pour les gaps).
Exercice 9 : Alignement avec Matrice de Similarités et Coût de Gap
Objectif : Généraliser le Programme 48 pour utiliser une matrice de similarités personnalisée et un coût de gap variable.
Énoncé : Dans les alignements biologiques (ADN), les scores ne sont pas fixes. Nous utilisons :
Une matrice de similarités (sim) pour le score d’alignement entre deux caractères spécifiques.
Une variable globale gap pour le coût de création d’un gap (-).
Question : Indiquez comment représenter la matrice de similarités en Python et modifiez le programme d’Alignement de Séquences (voir avant l’exercice 5) pour utiliser ces variables (sim et gap).
Exercice 10 : Nombre de Chemins sur une Grille
Objectif : Résoudre un problème de dénombrement par Programmation Dynamique.
Énoncé : Écrivez une fonction chemins(n, m) qui calcule le nombre de chemins possibles sur une grille de taille n×m (partant du coin supérieur gauche 0,0 jusqu’au coin inférieur droit n,m), en se déplaçant uniquement vers la droite ou vers le bas.
technique pour améliorer les Algorithmes Récursifs
La programmation dynamique est une puissante technique algorithmique qui transforme des solutions récursives « naïves » mais correctes en des solutions beaucoup plus efficaces en évitant les recalculs inutiles. Nous allons explorer cette méthode à travers un exemple classique, la suite de Fibonacci, et ensuite l’appliquer à un problème d’optimisation : le problème du sac à dos (Knapsack Problem).
1) La Suite de Fibonacci et le Recalcul Inutile
L’Approche Récursive Simple
La suite de Fibonacci (Fn) est définie par F0=0, F1=1, et Fn=Fn−1+Fn−2 pour n≥2. Une implémentation récursive directe en Python est la suivante :
Python
def fib_recursif(n):
if n < 2:
return n
else:
return fib_recursif(n-1) + fib_recursif(n-2)
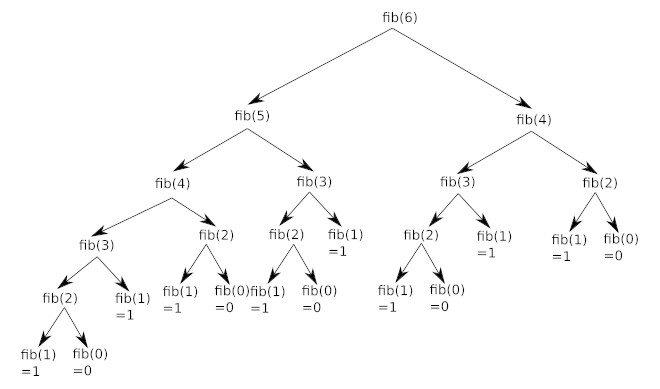
Pour calculer F6, l’exécution de ce code crée une structure arborescente d’appels. Si l’on déploie cet arbre pour F6, on constate une forte redondance des calculs.
Par exemple, le calcul de F4 est effectué deux fois, celui de F3 est effectué trois fois, etc. Cette duplication des efforts entraîne une complexité temporelle qui augmente de manière exponentielle (O(2n)), rendant cette approche impraticable pour de grandes valeurs de n.
En observant attentivement le schéma ci-dessus, vous avez remarqué que de nombreux calculs sont inutiles, car effectués 2 fois : par exemple, on retrouve le calcul de fib(4) à 2 endroits (en haut à droite et un peu plus bas à gauche) :
L’Optimisation par Mémorisation (Approche Descendante)
L’idée fondamentale est d’éviter de recalculer un résultat une fois qu’il a été obtenu. Nous allons « mémoriser » la solution de chaque sous-problème (Fk) dans un tableau ou un dictionnaire au fur et à mesure que nous le calculons.
Python
def fib_mem(n):
# Initialise un tableau pour stocker les résultats.
# Tous les résultats sont initialisés à 0 (ou une valeur "jamais calculée").
memo = [0] * (n + 1)
def f_mem(k):
if k == 0 or k == 1:
# Cas de base : on mémorise et retourne la valeur
memo[k] = k
return k
# Vérification 1 : Si le résultat est déjà mémorisé, on le retourne directement.
elif memo[k] > 0: # > 0 car F0=0 et on suppose n>0 pour les autres
return memo[k]
# Calcul : Si le résultat n'est pas mémorisé, on le calcule
else:
memo[k] = f_mem(k - 1) + f_mem(k - 2)
return memo[k]
return f_mem(n)
Principe de la Mémorisation :
Si la valeur de Fk a déjà été calculée (si elle est dans le tableau memo), on l’utilise sans faire de calcul supplémentaire.
Si la valeur de Fk n’a jamais été calculée, elle est calculée une unique fois, puis stockée dans le tableau memo pour une utilisation ultérieure.
Cette technique, appelée mémorisation (ou memoization), résout le problème Fk une seule fois, transformant la complexité exponentielle en une complexité beaucoup plus efficace, linéaire (O(n)). On parle ici de programmation dynamique descendante (top-down), car nous partons du problème principal (Fn) et le décomposons jusqu’aux cas de base (F0,F1).
2) La Programmation Dynamique
a) Introduction et Concepts Fondamentaux
La Programmation Dynamique (PD) est une méthode algorithmique pour résoudre des problèmes complexes en les décomposant en sous-problèmes plus simples. Inventée par Richard Bellman dans les années 1950, le terme « programmation » est à prendre dans le sens de planification ou d’ordonnancement d’un processus, et non de codage.
La PD s’applique efficacement aux problèmes qui présentent deux caractéristiques principales :
Sous-problèmes Optimaux : Une solution optimale au problème principal doit être construite à partir de solutions optimales à ses sous-problèmes (principe de Bellman).
Sous-problèmes Réciproques (Overlapping Subproblems) : Les sous-problèmes se recoupent, c’est-à-dire que le même sous-problème est rencontré et doit être résolu plusieurs fois.
La PD résout chaque sous-problème une seule fois et mémorise sa réponse, évitant ainsi le coût du recalcul.
b) Approche Ascendante (Bottom-Up)
L’approche ascendante (ou bottom-up) est la deuxième facette de la programmation dynamique. Au lieu d’utiliser la récursivité et la mémorisation (descendante), elle utilise une approche itérative (boucles) pour construire la solution des plus petits sous-problèmes vers le problème principal.
Fibonacci avec l’Approche Ascendante
Pour Fibonacci, l’idée est de remplir le tableau des résultats en partant de F0 et F1 et en montant jusqu’à Fn.
Python
def fib_asc(n):
if n < 2:
return n
# Crée un tableau pour stocker F0, F1, ..., Fn
tab = [0] * (n + 1)
tab[1] = 1 # Initialise F1
# Calcule F2, F3, ..., Fn de manière itérative
for i in range(2, n + 1):
tab[i] = tab[i - 1] + tab[i - 2]
return tab[n]
Ce programme est très simple. On construit Fi à partir de Fi−1 et Fi−2 qui ont déjà été calculés et stockés dans le tableau tab. Chaque Fi est calculé une seule fois.
3) Application à l’Optimisation : Le Problème du Sac à Dos (Knapsack Problem 0/1)
Le problème du sac à dos (0/1) est un problème d’optimisation classique : Étant donné un sac à dos de capacité maximale W et une liste d’objets, chacun avec un poids pi et une valeur vi, déterminer quels objets inclure dans le sac afin de maximiser la valeur totale sans dépasser la capacité W.
Ce problème ne peut pas être résolu de manière gloutonne (greedy) de manière fiable (par exemple, prendre toujours l’objet de plus grande valeur ou le meilleur rapport valeur/poids ne garantit pas la solution optimale globale).
Formulation Récursive et Sous-problèmes
Pour déterminer la valeur maximale que l’on peut obtenir avec une capacité w et les i premiers objets, nous avons deux choix pour l’objet i :
On inclut l’objet i : La valeur totale sera vi plus la valeur maximale obtenue avec la capacité restante w−pi et les i−1 premiers objets. (Possible seulement si pi≤w).
On n’inclut pas l’objet i : La valeur totale sera la valeur maximale obtenue avec la capacité w et les i−1 premiers objets.
La relation de récurrence (pour un objet i de poids pi et valeur vi, et une capacité w ) est :
Résolution par Programmation Dynamique Ascendante
Nous allons utiliser l’approche ascendante pour construire un tableau bidimensionnel DP, où DP[i][w] représente la valeur maximale que l’on peut obtenir en utilisant les i premiers objets pour une capacité de sac à dos w.
Exemple : Capacité W=5. Objets : O1(p=2,v=3), O2(p=3,v=4), O3(p=4,v=5).
Objets / Capacité (w)
0
1
2
3
4
5
Aucun objet (i=0)
0
0
0
0
0
0
O1 (p=2, v=3)
0
0
3
3
3
3
O2 (p=3, v=4)
0
0
3
4
4
7
O3 (p=4, v=5)
0
0
3
4
5
7
Exporter vers Sheets
Analyse du tableau :
DP[1][2]: Pour w=2 et seul l’objet O1 disponible. Puisque p1=2≤2, DP[1][2]=max(DP[0][2],v1+DP[0][2−2])=max(0,3+0)=3.
DP[2][5]: Pour w=5 et les objets O1,O2 disponibles. Puisque p2=3≤5, DP[2][5]=max(DP[1][5],v2+DP[1][5−3])=max(3,4+DP[1][2]). DP[1][2]=3. Donc max(3,4+3)=7. (On prend O2 et on utilise la meilleure valeur pour la capacité restante de 2 avec l’objet O1).
La solution optimale est donnée par DP[N][W] (ici DP[3][5]=7). Le problème est résolu avec une complexité en temps de O(N×W), où N est le nombre d’objets et W la capacité maximale, bien plus efficace qu’une approche par force brute (tester toutes les combinaisons).
Coût vs Bénéfice
Comme pour Fibonacci, la programmation dynamique permet un gain spectaculaire en complexité temporelle (le temps d’exécution). Cependant, elle nécessite l’utilisation d’une structure de données (le tableau memo ou le tableau DP) pour stocker les résultats des sous-problèmes.
Conclusion : La programmation dynamique échange de l’efficacité en temps contre une augmentation de l’utilisation de la mémoire (complexité spatiale).
L’Alignement de Séquences : Le Détective de l’ADN 🕵️♀️
1. Le Problème : Comparer l’ADN (ou des Mots !)
Imaginez que vous êtes un détective et que vous avez deux longues chaînes de caractères (comme des brins d’ADN, ou simplement deux mots) que vous devez comparer pour voir à quel point elles sont similaires.
C’est le problème de l’Alignement de Séquences : comment mettre en face les caractères de deux chaînes pour maximiser les correspondances.
La Règle du Jeu : L’Alignement
Pour comparer deux mots (par exemple, « GENOME » et « ENORME »), nous allons les écrire l’un sous l’autre. Nous pouvons insérer des trous (représentés par un tiret, -) dans l’une ou l’autre chaîne.
Contrainte essentielle : L’ordre des lettres ne doit jamais changer !
Contrainte essentielle : On n’aligne jamais deux trous ensemble (-- est interdit).
Alignement 1 (Bon)
Alignement 2 (Mauvais)
G E N O – M E
G – E N O M E
– E N O R M E
E – N O R M E
Exporter vers Sheets
Comment Compter les Points (Le Score)
Pour trouver le « meilleur » alignement, on utilise un système de points simple :
Action
Score
Match (caractères identiques)
+1 point (C’est super !)
Mismatch (caractères différents)
-1 point (C’est pas bon)
Gap (aligner un caractère avec un trou -)
-1 point (C’est pas bon)
Exporter vers Sheets
Exemple d’évaluation (GENO-ME vs -ENORME) :
Aligné
G vs –
E vs E
N vs N
O vs O
– vs R
M vs M
E vs E
Score
−1 (Gap)
+1 (Match)
+1 (Match)
+1 (Match)
−1 (Gap)
+1 (Match)
+1 (Match)
Exporter vers Sheets
Score Total : (−1)+(+1)+(+1)+(+1)+(−1)+(+1)+(+1)=3
Le but de l’algorithme est de trouver l’alignement qui donne le score maximal possible.
2. L’Approche « Bête et Méchante » (Récursivité Naïve)
Comment un ordinateur chercherait-il la meilleure solution ?
Il pourrait essayer de le faire de manière récursive, c’est-à-dire en se ramenant à un problème plus petit à chaque étape.
La Décomposition Récursive
Pour trouver le meilleur score entre deux mots M1 et M2, il suffit de regarder leurs derniers caractères (c1 et c2). Il y a toujours trois choix possibles pour l’alignement final :
Choix
Description de l’action finale
Score pour cette action
Le nouveau problème à résoudre
1. Diagonale
Aligner c1 avec c2
+1 (si c1=c2) ou −1 (si c1=c2)
Trouver le meilleur score pour M1 sans c1 et M2 sans c2
2. Verticale
Aligner c1 avec un trou -
−1 (Gap)
Trouver le meilleur score pour M1 sans c1 et M2 (entier)
3. Horizontale
Aligner c2 avec un trou -
−1 (Gap)
Trouver le meilleur score pour M1 (entier) et M2 sans c2
Exporter vers Sheets
Le Score Maximal pour M1 et M2 est simplement le maximum des scores obtenus par ces trois choix. On répète ensuite l’opération (récursion) sur les mots plus courts.
Le Problème des Recalculs (Pourquoi ça explose 💣)
Si on utilise cette approche, l’ordinateur va vite se retrouver à faire la même chose encore et encore.
Exemple : Pour aligner « GENOME » et « ENORME » :
Le Choix 1 vous demande d’aligner « GENOM » et « ENORM ».
Le Choix 2 vous demande d’aligner « GENOM » et « ENORME ».
Le Choix 3 vous demande d’aligner « GENOME » et « ENORM ».
Regardez le problème « GENOM » et « ENORM » : Il est calculé comme sous-problème dans les trois cas ! Ce problème est dit un sous-problème qui se chevauche.
Pour des mots de 20 lettres, ce phénomène de duplication se répète des milliards de fois, et le temps de calcul devient exponentiel (beaucoup trop lent !).
3. La Solution Intelligente : La Programmation Dynamique 🧠
Comme pour le problème du Rendu de Monnaie, nous allons utiliser la Programmation Dynamique (PD) pour éviter de recalculer les mêmes sous-problèmes. L’idée est de mémoriser chaque résultat.
Le Tableau de Scores (La « Carte »)
Au lieu de faire des appels récursifs et de tout oublier, nous allons construire un grand tableau à deux dimensions, appelé le tableau de scores (sc).
Si le premier mot (s1) a N lettres et le deuxième mot (s2) a M lettres, le tableau aura une taille de (N+1)×(M+1).
La case sc[i][j] va stocker le score maximal obtenu en alignant les i premières lettres de s1 avec les j premières lettres de s2.
sc
–
s2[0]
s2[1]
…
s2[M−1]
–
sc[0][0]
sc[0][1]
sc[0][2]
…
sc[0][M]
s1[0]
sc[1][0]
sc[1][1]
sc[1][2]
…
sc[1][M]
s1[1]
sc[2][0]
sc[2][1]
…
…
…
…
…
…
…
…
…
s1[N−1]
sc[N][0]
sc[N][1]
…
…
sc[N][M]
Exporter vers Sheets
Le résultat que nous cherchons est toujours la case en bas à droite : sc[N][M].
L’Initialisation des Bords (Les Cas Simples)
On commence par remplir la première ligne et la première colonne (les cas où l’on aligne un mot avec un mot vide).
sc[0][0]=0 : Aligner deux mots vides donne un score de 0.
sc[i][0]=−i : Pour aligner les i premières lettres de s1 avec un mot vide, nous devons faire i gaps (trous). Le coût est donc i×(−1)=−i.
sc[0][j]=−j : De même, aligner s2 avec un mot vide coûte −j.
Le Remplissage des Cases (Le Cœur du Calcul)
Pour remplir une case sc[i][j], nous utilisons la logique récursive des trois choix, mais au lieu d’appeler la fonction, nous regardons simplement les trois cases voisines qui ont déjà été calculées :
Voisin du Dessus (sc[i-1][j]) → Correspond au Choix 2 (Gap dans s2).
Voisin de Gauche (sc[i][j-1]) → Correspond au Choix 3 (Gap dans s1).
Voisin en Diagonale (sc[i-1][j-1]) → Correspond au Choix 1 (Alignement des deux derniers caractères s1[i−1] et s2[j−1]).
La formule de calcul (la relation de récurrence) devient :
Où score_match=+1 si s1[i−1]=s2[j−1], et −1 sinon.
L’Efficacité : Un Gain Incroyable 🚀
Grâce à cette méthode :
Chaque case du tableau n’est calculée qu’une seule fois !
Pour des mots de longueur N et M, le temps de calcul est proportionnel à la taille du tableau, soit N×M.
C’est une amélioration massive :
Récursivité naïve : Temps exponentiel (O(2max(N,M))). Impraticable au-delà de 20 lettres.
Programmation Dynamique : Temps polynomial (O(N×M)). C’est presque instantané même pour des séquences de milliers de caractères !
Ce tableau ne sert pas seulement à trouver le score maximal ; en remontant de la case finale à la case initiale en suivant les flèches du meilleur score à chaque fois, on peut reconstruire l’alignement optimal lui-même (comme vous le verrez dans certains exercices).
La méthode « Diviser pour régner » est un paradigme algorithmique puissant, souvent utilisé pour résoudre des problèmes complexes de manière élégante et efficace. L’idée est de décomposer un problème en plusieurs sous-problèmes, de les résoudre individuellement, puis de combiner leurs solutions pour obtenir la solution du problème initial.
Ce processus se décompose en trois phases principales :
DIVISER : Le problème initial est scindé en plusieurs sous-problèmes plus petits, généralement de nature similaire à l’original.
RÉGNER : Chaque sous-problème est résolu, souvent de manière récursive. La clé est que ces sous-problèmes sont plus simples à gérer que le problème de départ.
COMBINER : Les solutions des sous-problèmes sont fusionnées pour construire la solution finale du problème d’origine.
Les algorithmes qui emploient cette approche sont très souvent de nature récursive. Un exemple classique de cette méthode est le tri-fusion.
Le Tri-Fusion
Présentation
Le tri-fusion est un algorithme de tri efficace qui repose sur le principe « Diviser pour régner ». Il prend un tableau non trié en entrée et renvoie le même tableau, mais cette fois, dans l’ordre croissant.
Voici une implémentation simplifiée en pseudo-code des deux fonctions qui composent cet algorithme : FUSION et TRI-FUSION.
VARIABLE
A : tableau d'entiers
L, R : tableaux d'entiers
p, q, r, n1, n2 : entiers
k, i, j : entiers
DEBUTFUSION (A, p, q, r):
n1 ← q - p + 1
n2 ← r - q
créer tableau L[1..n1+1] et R[1..n2+1]
pour i ← 1 à n1:
L[i] ← A[p+i-1]
fin pour
pour j ← 1 à n2:
R[j] ← A[q+j]
fin pour
L[n1+1] ← ∞
R[n2+1] ← ∞
i ← 1
j ← 1
pour k ← p à r:
si L[i] ⩽ R[j]:
A[k] ← L[i]
i ← i + 1
sinon:
A[k] ← R[j]
j ← j + 1
fin si
fin pour
fin FUSION
TRI-FUSION(A, p, r):
si p < r:
q = (p + r) / 2
TRI-FUSION(A, p, q)
TRI-FUSION(A, q+1, r)
FUSION(A, p, q, r)
fin si
fin TRI-FUSION
L’appel initial pour trier un tableau A est TRI-FUSION(A, 1, A.longueur). Notez que dans cet algorithme, la fonction TRI-FUSION gère la phase de DIVISER, tandis que la fonction FUSION combine les phases de RÉGNER et de COMBINER.
Un aspect intéressant du tri-fusion est que la phase de « Régner » est trivialement simple : le processus de division se poursuit jusqu’à ce que les sous-problèmes ne contiennent qu’un seul élément. Trier un tableau d’un seul élément ne demande aucune opération, ce qui simplifie grandement la tâche.
La véritable magie opère lors de la phase de fusion. Imaginons que nous ayons deux tableaux déjà triés, B et C, et que nous souhaitions les fusionner en un nouveau tableau T. On compare simplement le premier élément de B avec le premier de C, on ajoute le plus petit des deux à T, puis on recommence avec les éléments restants. On continue jusqu’à ce que l’un des tableaux soit vide, puis on ajoute les éléments restants de l’autre tableau à la fin de T.
Complexité
Bien que le calcul rigoureux soit hors de la portée de ce cours, nous pouvons en estimer la complexité de manière intuitive. La phase de division, où les tableaux sont coupés en deux à plusieurs reprises, est liée à la fonction logarithmique en base 2, soit log_2(n). La phase de fusion, pour un tableau de n éléments, nécessite un nombre de comparaisons proportionnel à n. En combinant ces deux observations, nous arrivons à une complexité approximative de l’ordre de O(nlog(n)).
Comme le montre la comparaison des courbes, un algorithme en O(nlog(n)) est beaucoup plus performant pour de grandes valeurs de n qu’un algorithme en O(n²), comme le tri par insertion ou le tri par sélection.
Retour sur la dichotomie
Présentation
C’est une méthode pour trouver un nombre N dans une liste triée si elle y est présente ou pour prouver son absence. Le principe est de regarder la valeur centrale, soit c’est celle qu’on cherche soit la valeur trouvée nous permettra de déterminer dans laquelle des sous listes de part et d’autre de la valeur devrait se situer N. Une fois fait on applique la même démarche sur la sous liste en question. On continuera jusqu’à soit tomber sur N ou obtenir une liste ne divise cette sous liste et on repère dans laquelle des parties devrait se situer la valeur. On continue, avec des sous listes de plus en plus petites et se dirigeant progressivement vers des listes vides. Soit on tombe sur N avant cela, sinon la valeur n’est pas présente. Cette recherche repose sur le principe « Diviser pour régner ».
exercice (corrigé ici)
compléter le code ci dessous
def recherche(t, v, g, d):
"""renvoie une position de v dans t[g..d],
supposé trié, et None si elle ne s’y trouve pas"""
if g > d:
return None
m = (g + d) // 2
if t[m] < v:
return recherche(t, v, m + 1, d)
elif t[m] > v:
return recherche(t, v, g, m - 1)
else:
return m
def recherche_dichotomique(t, v):
"""renvoie une position de v dans le tableau t,
supposé trié, et None si elle ne s’y trouve pas"""
return recherche(t, v, 0, len(t) - 1)
L’appel initial pour trier un tableau A est TRI-FUSION(A, 1, A.longueur). Notez que dans cet algorithme, la fonction TRI-FUSION gère la phase de DIVISER, tandis que la fonction FUSION combine les phases de RÉGNER et de COMBINE
Activités et Exercices
Activité 1
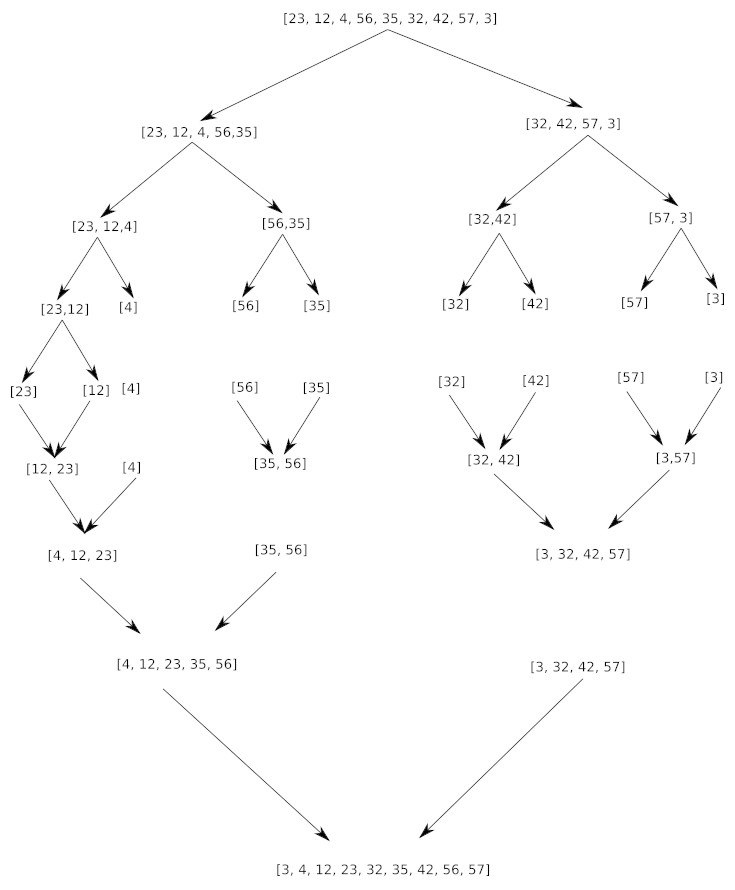
Appliquez l’algorithme de tri-fusion au tableau T= [23, 12, 4, 56, 35, 32, 42, 57, 3]. Vous pouvez créer un schéma et expliquer en détail la fusion de deux tableaux triés.
1. La phase de division
Le tri fusion commence par diviser de manière récursive le tableau initial en deux moitiés égales. Ce processus se poursuit jusqu’à ce que chaque sous-tableau ne contienne qu’un seul élément. À ce stade, le sous-tableau est considéré comme trié. C’est la partie « régner » de l’algorithme, qui est ici triviale.
2. La phase de fusion
Une fois que tous les sous-tableaux d’un seul élément sont formés, le tri fusion passe à la phase la plus importante : la fusion. L’idée est de fusionner deux sous-tableaux déjà triés en un seul grand tableau trié. C’est un processus simple qui se déroule en comparant les premiers éléments de chaque sous-tableau.
Prenons l’exemple de la fusion des deux tableaux triés suivants :
B = [4, 12, 23, 35, 56]
C = [3, 32, 42, 57]
Nous allons construire un nouveau tableau, T, qui contiendra le résultat de la fusion.
On compare le premier élément de B (4) avec le premier élément de C (3). Comme 3 est plus petit que 4, on le place dans T.
T = [3]
B = [4, 12, 23, 35, 56]
C = [32, 42, 57]
On compare à nouveau le premier élément restant de B (4) avec le premier élément de C (32). Comme 4 est plus petit, on le place dans T.
T = [3, 4]
B = [12, 23, 35, 56]
C = [32, 42, 57]
On continue ce processus :
On compare 12 et 32 : 12 est plus petit. On ajoute 12 à T.
On compare 23 et 32 : 23 est plus petit. On ajoute 23 à T.
On compare 35 et 32 : 32 est plus petit. On ajoute 32 à T.
On compare 35 et 42 : 35 est plus petit. On ajoute 35 à T.
On compare 56 et 42 : 42 est plus petit. On ajoute 42 à T.
On compare 56 et 57 : 56 est plus petit. On ajoute 56 à T.
À ce stade, le tableau B est vide. Il ne reste plus qu’un seul élément dans C (57). On l’ajoute directement à la fin du tableau T.
Le tableau final trié est donc : T = [3, 4, 12, 23, 32, 35, 42, 56, 57].
Ce processus de comparaison et d’ajout est répété pour toutes les fusions successives jusqu’à ce que tous les éléments soient rassemblés dans un seul tableau final trié.
Activité 2
Complétez le code Python suivant pour la fonction de tri-fusion :
def tri_fusion(tab):
def fusion(tab, p, q, r):
n1 = q-p+1
n2 = r-q
L = [0]*n1
R = [0]*n2
for i in range(n1):
L[i] = tab[p+i]
for j in range(n2):
R[j] = tab[q+j+1]
L.append(float("inf"))
R.append(float("inf"))
i = 0
j = 0
for k in range(p, r+1):
if L[i] <= R[j]:
tab[k] = L[i]
i = i + 1
else:
tab[k]=R[j]
j = j + 1
def tri_f(tab, p, r) :
if p < r:
q = (p + r) // 2
tri_f(tab, p, q)
tri_f(tab, q + 1, r)
fusion(tab, p, q, r)
tri_f(tab, p = 0, r = len(tab) - 1)
return tab
Activité 3
Complétez cette autre version du tri-fusion en Python, en utilisant le « slicing » :
def tri_fusion_slice(tab):
n = len(tab)
if n > 1:
mil = n // 2
L = tab[:mil]
R = tab[mil:]
tri_fusion_slice(L)
tri_fusion_slice(R)
i = 0
j = 0
k = 0
while i < len(L) and j < len(R):
if L[i] < R[j]:
tab[k] = L[i]
i += 1
else:
tab[k] = R[j]
j += 1
k += 1
while i < len(L):
tab[k] = L[i]
i += 1
k += 1
while j < len(R):
tab[k] = R[j]
j += 1
k += 1
Activité 4
En vous basant sur la vidéo disponible à cette adresse, implémentez l’algorithme de tri rapide (Quicksort) en Python, un autre algorithme basé sur le principe « Diviser pour régner ».
Exercices
Exercice 1 : Donnez la séquence des appels à la fonction de recherche dichotomique du cours pour les appels recherche_dichotomique([0,1,1,2,3,5,8,13,21], 13) et recherche_dichotomique([0,1,1,2,3,5,8,13,21], 12).
Exercice 2 : Quelles sont les deux listes renvoyées par une fonction coupe() à laquelle on passe la liste [8, 1, 3, 0, 1, 2, 5] ? L’ordre relatif est-il préservé ? Est-ce important ?
Exercice 3 : Réécrivez la fonction fusion en utilisant une boucle while au lieu de la récursivité.
Exercice 4 : Le problème des Tours de Hanoï est un jeu célèbre impliquant trois tiges et des disques de tailles différentes. Écrivez une fonction hanoi(n) qui affiche la solution pour n disques.
Exercice 5 : Combien de déplacements élémentaires faut-il au total pour déplacer N disques de la tour de départ à la tour d’arrivée dans le problème des Tours de Hanoï ?
Exercice 6 : Réécrivez l’exercice 4 en utilisant des piles (voir chapitre 5).
Exercice 7 : Écrivez une fonction qui effectue la rotation d’une image de 90 degrés en utilisant le principe « Diviser pour régner ».
Exercice 8 : Appliquez le principe « Diviser pour régner » pour multiplier deux entiers en utilisant la méthode de Karatsuba.
corrections
Exercice 1
Pour recherche_dichotomique([0,1,1,2,3,5,8,13,21], 13) :
recherche(t, 13, 0, 8)
recherche(t, 13, 5, 8)
recherche(t, 13, 7, 8)
À ce moment, l’index m est 7, où se trouve la valeur 13.
Pour recherche_dichotomique([0,1,1,2,3,5,8,13,21], 12) :
recherche(t, 12, 0, 8)
recherche(t, 12, 5, 8)
recherche(t, 12, 7, 8)
recherche(t, 12, 7, 6)
À ce moment, l’indice de gauche g est supérieur à l’indice de droite d, et la recherche se termine avec le résultat None.
Exercice 2
Les deux listes renvoyées sont [5, 1, 3, 8] et [2, 0, 1]. L’ordre relatif des éléments est inversé, car la fonction ajoute les éléments au début des nouvelles listes. Cependant, ce n’est pas important pour le tri-fusion, car les deux listes sont triées avant d’être fusionnées, ce qui annule l’inversion initiale.
Exercice 3
def fusion(l1, l2):
lst = None
while l1 is not None or l2 is not None:
if l1 is not None and (l2 is None or l1.valeur <= l2.valeur):
lst, l1 = Cellule(l1.valeur, lst), l1.suivante
else:
lst, l2 = Cellule(l2.valeur, lst), l2.suivante
# Puis on inverse la liste lst
r = None
while lst is not None:
r, lst = Cellule(lst.valeur, r), lst.suivante
return r
Exercice 4
def deplace(a, b, c, k):
"""Déplace k disques de la tour a vers la tour b, en se servant de la tour c comme intermédiaire"""
if k > 0:
deplace(a, c, b, k - 1)
print("déplace de", a, "vers", b)
deplace(c, b, a, k - 1)
def hanoi(n):
deplace(1, 3, 2, n)
Exercice 5
Pour déplacer $N$ disques, il faut au total $2^N - 1$ déplacements élémentaires. La preuve se fait par récurrence :
* Pour $N=1$, il faut $2^1 - 1 = 1$ déplacement.
* Si l'on suppose qu'il faut $2^{N-1} - 1$ déplacements pour $N-1$ disques, alors pour $N$ disques, on aura :
* $2^{N-1} - 1$ déplacements pour déplacer les $N-1$ premiers disques de la tour de départ à la tour intermédiaire.
* 1 déplacement pour le plus grand disque de la tour de départ à la tour d'arrivée.
* $2^{N-1} - 1$ déplacements pour déplacer les $N-1$ disques de la tour intermédiaire à la tour d'arrivée.
* Total : $(2^{N-1} - 1) + 1 + (2^{N-1} - 1) = 2 \times 2^{N-1} - 1 = 2^N - 1$.
Exercice 6
def hanoi_piles(n):
a = Pile()
for i in range(n, 0, -1):
a.empiler(i)
deplace(a, Pile(), Pile(), n)
def deplace(a, b, c, k):
"""déplace k disques de la pile a vers la pile b, en se servant de la pile c comme intermédiaire"""
if k > 0:
deplace(a, c, b, k - 1)
b.empiler(a.depiler())
deplace(c, b, a, k - 1)
Exercice 7
def rotation_aux(px, x, y, t):
'''on va faire la rotation de l'image située entre les pixels de coordonnées (x,y) et (x+t,y+t)'''
if t == 1:
return
t //= 2
rotation_aux(px, x, y, t)
rotation_aux(px, x + t, y, t)
rotation_aux(px, x, y + t, t)
rotation_aux(px, x + t, y + t, t)
for x1 in range(x, x + t):
for y1 in range(y, y + t):
px[x1, y1 + t]=px[x1, y1]
px[x1 + t, y1 + t]= px[x1, y1 + t]
px[x1 + t, y1]= px[x1 + t, y1 + t]
px[x1, y1] =px[x1 + t, y1]
def rotation(px, taille):
rotation_aux(px, 0, 0, taille)
Exercice 8
voici deux version du programme en Python. Il faudra copier l’une ou l’autre (car les noms de fonctions sont les mêmes dans les deux versions)
#en base 10
def taille(x):
n = 1
while x > 0:
x //= 10
n += 1
return n
def karatsuba(x, y, n):
"""multiplie x et y par la méthode de Karatsuba"""
if n <= 1:
return x * y
n //= 2
a, b = x // 10**n, x % 10**n
c, d = y // 10**n, y % 10**n
ac = karatsuba(a, c, n)
bd = karatsuba(b, d, n)
abcd = karatsuba(a - b, c - d, n)
return (ac * 10 ** (2 * n)) + ((ac + bd - abcd) * 10**n) + bd
def mult(x, y):
n = max(taille(abs(x)), taille(abs(y)))
return karatsuba(x, y, n)
print(mult(2457,6819))
# en base 2
def taille(x):
n = 1
while x > 0:
x //= 2
n += 1
return n
def karatsuba(x, y, n):
"""multiplie x et y par la méthode de Karatsuba"""
if n <= 1:
return x * y
n //= 2
m = 1 << n
a, b = x >> n, x % m
c, d = y >> n, y % m
ac = karatsuba(a, c, n)
bd = karatsuba(b, d, n)
abcd = karatsuba(a - b, c - d, n)
return (ac << (2 * n)) + ((ac + bd - abcd) << n) + bd
def mult(x, y):
n = max(taille(abs(x)), taille(abs(y)))
return karatsuba(x, y, n)
La méthode « Diviser pour régner » est un paradigme algorithmique puissant, souvent utilisé pour résoudre des problèmes complexes de manière élégante et efficace. L’idée est de décomposer un problème en plusieurs sous-problèmes, de les résoudre individuellement, puis de combiner leurs solutions pour obtenir la solution du problème initial.
Ce processus se décompose en trois phases principales :
DIVISER : Le problème initial est scindé en plusieurs sous-problèmes plus petits, généralement de nature similaire à l’original.
RÉGNER : Chaque sous-problème est résolu, souvent de manière récursive. La clé est que ces sous-problèmes sont plus simples à gérer que le problème de départ.
COMBINER : Les solutions des sous-problèmes sont fusionnées pour construire la solution finale du problème d’origine.
Les algorithmes qui emploient cette approche sont très souvent de nature récursive. Un exemple classique de cette méthode est le tri-fusion.
Le Tri-Fusion
Présentation
Le tri-fusion est un algorithme de tri efficace qui repose sur le principe « Diviser pour régner ». Il prend un tableau non trié en entrée et renvoie le même tableau, mais cette fois, dans l’ordre croissant.
Voici une implémentation simplifiée en pseudo-code des deux fonctions qui composent cet algorithme : FUSION et TRI-FUSION.
VARIABLE
A : tableau d'entiers
L, R : tableaux d'entiers
p, q, r, n1, n2 : entiers
k, i, j : entiers
DEBUT
FUSION (A, p, q, r):
n1 ← q - p + 1
n2 ← r - q
créer tableau L[1..n1+1] et R[1..n2+1]
pour i ← 1 à n1:
L[i] ← A[p+i-1]
fin pour
pour j ← 1 à n2:
R[j] ← A[q+j]
fin pour
L[n1+1] ← ∞
R[n2+1] ← ∞
i ← 1
j ← 1
pour k ← p à r:
si L[i] ⩽ R[j]:
A[k] ← L[i]
i ← i + 1
sinon:
A[k] ← R[j]
j ← j + 1
fin si
fin pour
fin FUSION
TRI-FUSION(A, p, r):
si p < r:
q = (p + r) // 2
TRI-FUSION(A, p, q)
TRI-FUSION(A, q+1, r)
FUSION(A, p, q, r)
fin si
fin TRI-FUSION
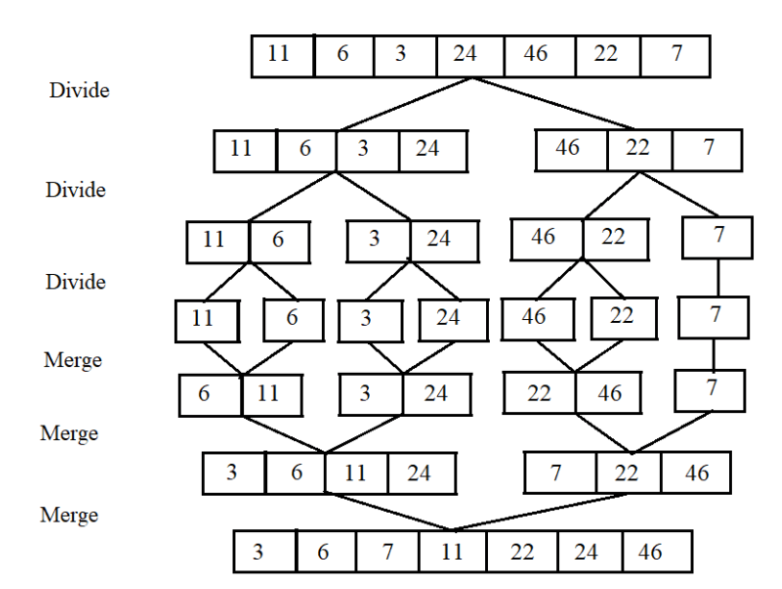
visuellement ça donne ça :
L’appel initial pour trier un tableau A est TRI-FUSION(A, 1, A.longueur). Notez que dans cet algorithme, la fonction TRI-FUSION gère la phase de DIVISER, tandis que la fonction FUSION combine les phases de RÉGNER et de COMBINER.
Un aspect intéressant du tri-fusion est que la phase de « Régner » est trivialement simple : le processus de division se poursuit jusqu’à ce que les sous-problèmes ne contiennent qu’un seul élément. Trier un tableau d’un seul élément ne demande aucune opération, ce qui simplifie grandement la tâche.
La véritable magie opère lors de la phase de fusion. Imaginons que nous ayons deux tableaux déjà triés, B et C, et que nous souhaitions les fusionner en un nouveau tableau T. On compare simplement le premier élément de B avec le premier de C, on ajoute le plus petit des deux à T, puis on recommence avec les éléments restants. On continue jusqu’à ce que l’un des tableaux soit vide, puis on ajoute les éléments restants de l’autre tableau à la fin de T.
Complexité
Bien que le calcul rigoureux soit hors de la portée de ce cours, nous pouvons en estimer la complexité de manière intuitive. La phase de division, où les tableaux sont coupés en deux à plusieurs reprises, est liée à la fonction logarithmique en base 2, soit log_2(n). La phase de fusion, pour un tableau de n éléments, nécessite un nombre de comparaisons proportionnel à n. En combinant ces deux observations, nous arrivons à une complexité approximative de l’ordre de O(nlog(n)).
Comme le montre la comparaison des courbes, un algorithme en O(nlog(n)) est beaucoup plus performant pour de grandes valeurs de n qu’un algorithme en O(n²), comme le tri par insertion ou le tri par sélection.
Retour sur la dichotomie
Présentation
C’est une méthode pour trouver un nombre N dans une liste triée si elle y est présente ou pour prouver son absence. Le principe est de regarder la valeur centrale, soit c’est celle qu’on cherche soit la valeur trouvée nous permettra de déterminer dans laquelle des sous listes de part et d’autre de la valeur devrait se situer N. Une fois fait on applique la même démarche sur la sous liste en question. On continuera jusqu’à soit tomber sur N ou obtenir une liste ne divise cette sous liste et on repère dans laquelle des parties devrait se situer la valeur. On continue, avec des sous listes de plus en plus petites et se dirigeant progressivement vers des listes vides. Soit on tombe sur N avant cela, sinon la valeur n’est pas présente. Cette recherche repose sur le principe « Diviser pour régner ».
def recherche(t, v, g, d):
"""renvoie une position de v dans t[g..d],
supposé trié, et None si elle ne s’y trouve pas"""
...
def recherche_dichotomique(t, v):
"""renvoie une position de v dans le tableau t,
supposé trié, et None si elle ne s’y trouve pas"""
return ...
L’appel initial pour trier un tableau A est TRI-FUSION(A, 1, A.longueur). Notez que dans cet algorithme, la fonction TRI-FUSION gère la phase de DIVISER, tandis que la fonction FUSION combine les phases de RÉGNER et de COMBINE
Activités et Exercices
Activité 1
Appliquez l’algorithme de tri-fusion au tableau T= [23, 12, 4, 56, 35, 32, 42, 57, 3]. Vous pouvez créer un schéma et expliquer en détail la fusion de deux tableaux triés.
Activité 2
Complétez le code Python suivant pour la fonction de tri-fusion :
def tri_fusion(tab):
# Fonction pour fusionner deux sous-tableaux triés
def fusion(tab, p, q, r):
n1 = q - p + 1
n2 = r - q
# On crée deux tableaux temporaires, L et R
L = [0] * n1
R = [0] * n2
# On remplit les tableaux L et R
for i in range(n1):
L[i] = tab[p + i]
for j in range(n2):
R[j] = tab[q + j + 1]
# On ajoute un 'sentinelle' (une valeur très grande) à la fin de chaque tableau
# Cela nous permet d'éviter de vérifier si un tableau est vide
L.append(float("inf"))
R.append(float("inf"))
i = 0 # Indice pour le tableau L
j = 0 # Indice pour le tableau R
# On parcourt le tableau original pour y placer les éléments triés
for k in range(p, r + 1):
if __________: # Quelle est la condition pour savoir quel élément choisir ?
tab[k] = L[i]
i = i + 1
else:
tab[k] = R[j]
j = j + 1
# Fonction principale récursive pour le tri
def tri_f(tab, p, r):
# Quelle est la condition pour arrêter la récursion ?
if __________:
# On calcule le milieu
q = _________
# 1. On trie la première moitié du tableau
tri_f(tab, p, q)
# 2. On trie la deuxième moitié du tableau
tri_f(tab, q + 1, r)
# 3. On fusionne les deux moitiés triées
fusion(tab, p, q, r)
# Appel initial de la fonction de tri
tri_f(tab, p=0, r=_________) # De quelle borne à quelle borne allons-nous trier le tableau ?
return tab
Activité 3
Complétez cette autre version du tri-fusion en Python, en utilisant le « slicing » :
def tri_fusion_slice(tab):
n = len(tab)
# Condition d'arrêt de la récursion
if __________: # Quand arrêtons-nous de diviser le tableau ?
# Calcul du point milieu pour diviser le tableau
mil = _________
# On divise le tableau en deux sous-tableaux (slicing)
L = tab[:mil]
R = tab[mil:]
# Appels récursifs pour trier chaque moitié
tri_fusion_slice(L)
tri_fusion_slice(R)
# Indices pour parcourir les tableaux L, R et le tableau final
i = 0
j = 0
k = 0
# Boucle principale de fusion : on compare et on place les éléments
while i < len(L) and j < len(R):
if __________: # Quelle est la condition pour choisir l'élément de L ?
tab[k] = L[i]
i += 1
else:
tab[k] = R[j]
j += 1
k += 1
# Boucles pour ajouter les éléments restants (s'il y en a)
while i < len(L):
tab[k] = L[i]
i += 1
k += 1
while __________: # Quelle est la condition pour ajouter les éléments restants de R ?
tab[k] = R[j]
j += 1
k += 1
Activité 4
En vous basant sur la vidéo disponible à cette adresse, implémentez l’algorithme de tri rapide (Quicksort) en Python, un autre algorithme basé sur le principe « Diviser pour régner ».
Exercices
Exercice 1 : Donnez la séquence des appels à la fonction de recherche dichotomique du cours pour les appels recherche_dichotomique([0,1,1,2,3,5,8,13,21], 13) et recherche_dichotomique([0,1,1,2,3,5,8,13,21], 12).
Exercice 2 : Quelles sont les deux listes renvoyées par une fonction coupe() à laquelle on passe la liste [8, 1, 3, 0, 1, 2, 5] ? L’ordre relatif est-il préservé ? Est-ce important ?
Exercice 3 : Réécrivez la fonction fusion en utilisant une boucle while au lieu de la récursivité.
Exercice 4 : Le problème des Tours de Hanoï est un jeu célèbre impliquant trois tiges et des disques de tailles différentes. Écrivez une fonction hanoi(n) qui affiche la solution pour n disques.
Exercice 5 : Combien de déplacements élémentaires faut-il au total pour déplacer N disques de la tour de départ à la tour d’arrivée dans le problème des Tours de Hanoï ?
Exercice 6 : Réécrivez l’exercice 4 en utilisant des piles (voir chapitre 5).
Exercice 7 : Écrivez une fonction qui effectue la rotation d’une image de 90 degrés en utilisant le principe « Diviser pour régner ». indications et voir photo plus bas.
Exercice 8 : Appliquez le principe « Diviser pour régner » pour multiplier deux entiers en utilisant la méthode de Karatsuba.
Un problème classique et élégant à résoudre avec la récursivité est de générer toutes les permutations d’une liste (toutes les façons d’ordonner ses éléments).
Par exemple, pour [1, 2, 3], les permutations sont [1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1].
Comment ça marche pour trouver les permutation des éléments d’une liste
On choisit un élément de la liste.
On identifie ce qui reste d’éléments à traiter
On lance un appel de notre fonction récursive pour générer une liste des permutations de ce qui reste d’éléments à traiter (autrement dit on crée un liste des permutations des éléments restants) cet appel peut en provoquer un autre qui en provoque un autre…jusqu’à ce que le reste ne contienne qu’un élément et dans ce cas la liste renvoyée est très courte, elle ne contient qu’un élément le fameux élément restant.
On combine l’élément choisi avec toutes les permutations du reste.
Mini-Application 1 : Les Arrangements de Mots ✍️
Essayez de compléter cette fonction pour qu’elle affiche toutes les permutations d’une chaîne de caractères (par exemple, « ABC »).
Python
def permuter(chaine):
if len(chaine) == 1:
return [chaine]
permutations = []
for i, char in enumerate(chaine):
# On choisit un caractère
reste = chaine[:i] + chaine[i+1:] # Le reste de la chaîne
# On permute le reste
permutations_restantes = permuter(reste)
# On combine le caractère choisi avec les permutations du reste
for p_reste in permutations_restantes:
permutations.append(char + p_reste)
return permutations
print(permuter("ABC"))
C’est un peu plus complexe, mais ça montre bien la puissance de la récursivité pour découper un gros problème en petits morceaux !
🎨 La Beauté des Fractales avec Turtle 🐢
La récursivité est la reine des fractales, ces formes géométriques complexes qui se répètent à l’infini à différentes échelles. Le flocon de Koch est un exemple magnifique.
Mini-Challenge 4 : Le Flocon Magique ❄️
Regardez cette vidéo sur le flocon de Koch (ou cherchez « flocon de Koch animation » si le lien ne marche pas).
Ensuite, analysez et testez le code suivant. Concentrez-vous sur les paramètres longueur et n (le nombre d’étapes de récursivité).
Python
import turtle as t
t.speed(0) # Vitesse maximale pour un dessin rapide
t.penup()
t.goto(-150, 90) # Position de départ pour que le flocon soit bien centré
t.pendown()
def koch(longueur, n):
if n == 0:
t.forward(longueur)
else:
# Chaque segment est remplacé par 4 segments plus petits
koch(longueur / 3, n - 1)
t.left(60)
koch(longueur / 3, n - 1)
t.right(120)
koch(longueur / 3, n - 1)
t.left(60)
koch(longueur / 3, n - 1)
def flocon(taille, etape):
for _ in range(3): # Un flocon est composé de 3 segments de Koch
koch(taille, etape)
t.right(120)
flocon(300, 4) # Essayez différentes valeurs pour taille et etape !
t.done() # Garde la fenêtre ouverte
Le secret du flocon de Koch réside dans la fonction koch : si n est 0, on dessine juste un segment droit. Sinon, on remplace ce segment par 4 segments plus petits, en tournant de 60 ou 120 degrés, et on appelle koch récursivement pour chacun de ces segments ! C’est le principe des fractales : une petite partie ressemble au tout.
Fin du cours
Défi 1 : Le Compteur d’Étoiles Filantes 🌠
Imaginez que chaque nuit, le nombre d’étoiles filantes que vous voyez est la somme du nombre d’étoiles vues la veille, la veille de la veille, etc., jusqu’à la première nuit où vous n’en avez vu qu’une seule !
Exercice : Créez une fonction récursive nommée compte_etoiles_filantes(jour) qui calcule le nombre cumulé d’étoiles filantes observées jusqu’à un certain jour. Par définition, au jour 0, vous avez vu 1 étoile filante. Pour tout jour n > 0, le nombre d’étoiles est n s’ajoute au nombre d’étoiles des jour n-1 jusqu’à 0.
Prérequis : Maîtrise des concepts de base des fonctions (définition, appel, return). Voir la Correction du Défi 1
Analyse du problème : La définition nous est donnée :
Cas de base : compte_etoiles_filantes(0) doit retourner 1.
Cas récursif : compte_etoiles_filantes(n) doit retourner n + compte_etoiles_filantes(n-1).
Code :
Python
def compte_etoiles_filantes(jour):
"""
Calcule le nombre cumulé d'étoiles filantes jusqu'à un certain jour.
jour (int): Le numéro du jour (>= 1).
Retourne (int): Le nombre cumulé d'étoiles.
"""
if jour == 1: # Cas de base : au jour 1, on a vu 1 étoile.
return 1
else: # Cas récursif : le nombre d'étoiles jusqu'au jour n est (n + le nombre d'étoiles vues jusqu'au jour n-1).
return jour + compte_etoiles_filantes(jour - 1)
# Tests rapides :
print(f"Étoiles au jour 1 : {compte_etoiles_filantes(2)}") # Attendu : 3 (2 + 1)
print(f"Étoiles au jour 3 : {compte_etoiles_filantes(3)}") # Attendu : 6 (3 + 2 + 1)
print(f"Étoiles au jour 5 : {compte_etoiles_filantes(5)}") # Attendu : 15 (5 + 4 + 3 + 2 + 1 )
Défi 2 : La Danse des insectes de Syracuse 🐜
Imaginez un insecte magicien. Chaque jour, si son nombre de pattes est pair, il en perd la moitié. Si son nombre de pattes est impair, son nombre de pattes triple et gagne une patte supplémentaire en prime. La légende dit que toutes les fourmis finissent toujours par n’avoir qu’une seule patte.
Exercice : Écrivez une fonction récursive danse_syracuse(nombre_pattes) qui prend en paramètre le nombre de pattes initial de l’insecte et affiche la séquence des nombres de pattes jour après jour, jusqu’à ce que l’insecte n’en ait plus qu’une. On supposera nombre_pattes est un entier positif strictement supérieur à 1.
Prérequis : Maîtrise des opérateurs modulo (%) et division entière (//). Comprendre l’importance du cas de base pour éviter la récursion infinie.
Analyse du problème : La suite de Syracuse est définie par deux règles :
Si u_n est pair : u_{n+1} = u_n / 2
Si u_n est impair : u_{n+1} = 3 * u_{n} + 1 Le cas de base est lorsque u_{n] atteint 1.
Code :
Python
def danse_syracuse(nombre_pattes):
"""
Affiche la séquence des nombres de pattes d'un insecte de Syracuse.
nombre_pattes (int): Le nombre de pattes actuel de l'insecte (doit être > 1).
"""
print(nombre_pattes) # On affiche le nombre de pattes actuel
if nombre_pattes == 1: # Cas de base : l'insecte n'a plus qu'une patte
return
if nombre_pattes % 2 == 0: # Si le nombre de pattes est pair
danse_syracuse(nombre_pattes // 2)
else: # Si le nombre de pattes est impair
danse_syracuse(3 * nombre_pattes + 1)
# Tests rapides :
print("Séquence pour 6 :")
danse_syracuse(6)
# Attendu : 6 3 10 5 16 8 4 2 1
print("\nSéquence pour 27 :")
danse_syracuse(27)
# La séquence est plus longue, mais doit finir par 1.
Défi 3 : La suite des Nombres Étranges 🎶
Imaginez une suite où chaque valeur dépend des deux valeurs précédentes et d’une constante. La première valeur est notée ‘A’ et la deuxième note est notée ‘B’. Ensuite, chaque nouvelle note est calculée en combinant trois fois la note précédente, deux fois celle d’avant et en ajoutant cinq .
Exercice : Écrivez une fonction récursive suite_etrange(n, note_A, note_B) qui renvoie la valeur de la n-ième note de cette suite, en considérant que n=0 correspond à note_A et n=1 à note_B.
Prérequis : Compréhension des suites définies par récurrence sur plusieurs termes précédents.
Analyse du problème : La suite est définie par :
u_0 = a
u_1 = b
u_n = 3 * u_{n-1} + 2 * u_{n-2} + 5 pour n >= 2
Les cas de base sont n=0 et n=1. Pour les autres n, c’est un appel récursif.
Code :
Python
def suite_etrange(n, note_A, note_B):
"""
Renvoie le n-ième terme d'une suite récursive avec deux cas de base.
n (int): L'indice du terme à calculer (>= 0).
note_A (float/int): La valeur du terme u_0.
note_B (float/int): La valeur du terme u_1.
Retourne (float/int): Le n-ième terme de la suite.
"""
if n == 0: # Premier cas de base
return note_A
elif n == 1: # Deuxième cas de base
return note_B
else: # Cas récursif
return 3 * suite_etrange(n - 1, note_A, note_B) + 2 * suite_etrange(n - 2, note_A, note_B) + 5
# Tests rapides :
print(f"Mélodie à l'indice 0 (A=10, B=20): {melodie_etrange(0, 10, 20)}") # Attendu : 10
print(f"Mélodie à l'indice 1 (A=10, B=20): {melodie_etrange(1, 10, 20)}") # Attendu : 20
print(f"Mélodie à l'indice 2 (A=10, B=20): {melodie_etrange(2, 10, 20)}") # Attendu : 3*20 + 2*10 + 5 = 85
print(f"Mélodie à l'indice 3 (A=10, B=20): {melodie_etrange(3, 10, 20)}") # Attendu : 3*85 + 2*20 + 5 = 300
Défi 4 : Le Labyrinthe des Chiffres Croissants 🔢➡️🔢
Imaginez que vous êtes dans un labyrinthe où chaque pièce est un chiffre. Vous ne pouvez avancer que vers des pièces avec un chiffre plus élevé, et vous voulez visiter toutes les pièces entre un point de départ et un point d’arrivée.
Exercice : Créez une fonction récursive explore_labyrinthe(depart, arrivee) qui affiche tous les entiers de depart à arrivee (inclus), dans l’ordre croissant.
Prérequis : Maîtrise des opérateurs de comparaison et des structures conditionnelles (if). Voir la Correction du Défi 4
Analyse du problème : Le cas de base est lorsque depart dépasse arrivee. Sinon, on affiche depart et on explore le reste du labyrinthe en augmentant depart.
Code :
Python
def explore_labyrinthe(depart, arrivee):
"""
Affiche tous les entiers entre depart et arrivee (inclus) dans l'ordre.
depart (int): L'entier de départ.
arrivee (int): L'entier d'arrivée.
"""
if depart > arrivee: # Cas de base : on a dépassé l'arrivée
return
else: # Cas récursif
print(depart, end=" ") # Afficher l'entier actuel
explore_labyrinthe(depart + 1, arrivee) # Appeler la fonction pour l'entier suivant
# Tests rapides :
print("Exploration de 0 à 3 :")
explore_labyrinthe(0, 3) # Attendu : 0 1 2 3
print("\nExploration de 5 à 5 :")
explore_labyrinthe(5, 5) # Attendu : 5
print("\nExploration de 7 à 4 :")
explore_labyrinthe(7, 4) # Attendu : rien (condition depart > arrivee est vraie immédiatement)
Défi 5 : Le Décodeur de Clés Secrètes (PGCD) 🔑
Pour déverrouiller une porte secrète, vous avez besoin du plus grand commun diviseur (PGCD) de deux nombres. La machine utilise un algorithme où si le deuxième nombre est zéro, le PGCD est le premier nombre. Sinon, le PGCD est celui du deuxième nombre et du reste de la division du premier par le deuxième.
Exercice : Écrivez une fonction récursive decode_cle_secrete(a, b) qui renvoie le PGCD de deux entiers positifs a et b, en utilisant l’algorithme d’Euclide.
Prérequis : Connaissance de l’algorithme d’Euclide pour le PGCD, et de l’opérateur modulo (%).
Analyse du problème : L’algorithme d’Euclide est intrinsèquement récursif : on fait des divisions euclidiennes successives et à chaque fois le diviseur devient le nouveau dividende et le reste devient le nouveau diviseur. Du coup le PGCD de la paire de base a la même valeur que la paire suivante, qui aura la même valeur que … De plus on est censé s’arrêter et prendre le dernier reste non nul. Vérifier que tout ça peut être traduit de la manière suivante :
Cas de base : Si b est 0, le PGCD est a.
Cas récursif : Sinon, PGCD(a, b) = PGCD(b, a % b).
Code :
Python
def decode_cle_secrete(a, b):
"""
Calcule le Plus Grand Commun Diviseur (PGCD) de deux entiers positifs.
a (int): Le premier entier.
b (int): Le deuxième entier.
Retourne (int): Le PGCD de a et b.
"""
if b == 0: # Cas de base de l'algorithme d'Euclide
return a
else: # Cas récursif
return decode_cle_secrete(b, a % b)
# Tests rapides :
print(f"PGCD(48, 18) : {decode_cle_secrete(48, 18)}") # Attendu : 6
print(f"PGCD(17, 5) : {decode_cle_secrete(17, 5)}") # Attendu : 1
print(f"PGCD(100, 25) : {decode_cle_secrete(100, 25)}") # Attendu : 25
print(f"PGCD(7, 0) : {decode_cle_secrete(7, 0)}") # Attendu : 7
Défi 6 : L’Inspecteur de Chiffres 🕵️♀️
Vous êtes un inspecteur et vous devez compter le nombre de chiffres qui composent un suspect numérique. Chaque fois que vous examinez un chiffre, vous retirez ce chiffre et comptez le reste. Par exemple si vous inspectez 179, vous allez prendre 9, et il restera 17, puis vous prendrez 7, il restera 1, vous le prenez il ne reste rien. Vous avez pris successivement trois chiffres avant de ne rien avoir à prendre donc, la réponse vous allez rendre/afficher est 3. Ça à l’air simple comme ça, mais passer de 179 à 17 puis à 1 et enfin à rien, ça va vous demander un peu de réflexion.
Exercice : Écrivez une fonction récursive inspecteur_de_chiffres(n) qui prend un entier positif ou nul n et renvoie son nombre de chiffres décimaux.
Prérequis : Maîtrise des opérateurs de division entière (//). Gérer le cas n=0 correctement.
Analyse du problème :
Le nombre de chiffres d’un nombre entre 0 et 9 est 1. C’est notre cas de base.
Pour un nombre n plus grand, le nombre de chiffres est 1 (pour le chiffre des unités) plus le nombre de chiffres de n // 10.
Code :
Python
def inspecteur_de_chiffres(n):
"""
Renvoie le nombre de chiffres décimaux d'un entier positif ou nul.
n (int): L'entier à analyser (>= 0).
Retourne (int): Le nombre de chiffres.
"""
if n < 10: # Cas de base : si n est un chiffre (0-9)
return 1
else: # Cas récursif : retirer le dernier chiffre et compter le reste
return 1 + inspecteur_de_chiffres(n // 10)
# Tests rapides :
print(f"Chiffres de 0 : {inspecteur_de_chiffres(0)}") # Attendu : 1
print(f"Chiffres de 7 : {inspecteur_de_chiffres(7)}") # Attendu : 1
print(f"Chiffres de 42 : {inspecteur_de_chiffres(42)}") # Attendu : 2
print(f"Chiffres de 12345 : {inspecteur_de_chiffres(12345)}") # Attendu : 5
Défi 7 : Le Compteur de Bits Lumineux 💡
Dans le monde binaire, certains bits sont « lumineux » (valent 1) et d’autres sont « éteints » (valent 0). Vous devez compter combien de bits lumineux il y a dans la représentation binaire d’un nombre.
Exercice : Écrivez une fonction récursive compteur_bits_lumineux(n) qui prend un entier positif ou nul n et renvoie le nombre de bits valant 1 dans sa représentation binaire.
Prérequis : Connaissance des opérateurs binaires (% 2 pour le dernier bit, // 2 pour décaler à droite). Voir la Correction du Défi 7
Analyse du problème :
Le cas de base est lorsque n est 0, il n’y a aucun bit 1.
Pour n > 0, on vérifie le dernier bit (n % 2). S’il vaut 1, on l’ajoute au compte. Ensuite, on compte les bits 1 dans le reste du nombre (n // 2).
Code :
Python
def compteur_bits_lumineux(n):
"""
Renvoie le nombre de bits valant 1 dans la représentation binaire d'un entier.
n (int): L'entier positif ou nul.
Retourne (int): Le nombre de bits à 1.
"""
if n == 0: # Cas de base : plus de bits à examiner
return 0
else: # Cas récursif
# On ajoute 1 si le dernier bit est 1 (n % 2)
# Puis on compte les bits 1 dans le reste du nombre (n // 2)
return (n % 2) + compteur_bits_lumineux(n // 2)
# Tests rapides :
print(f"Bits lumineux de 0 (0b0) : {compteur_bits_lumineux(0)}") # Attendu : 0
print(f"Bits lumineux de 1 (0b1) : {compteur_bits_lumineux(1)}") # Attendu : 1
print(f"Bits lumineux de 2 (0b10) : {compteur_bits_lumineux(2)}") # Attendu : 1
print(f"Bits lumineux de 3 (0b11) : {compteur_bits_lumineux(3)}") # Attendu : 2
print(f"Bits lumineux de 255 (0b11111111) : {compteur_bits_lumineux(255)}") # Attendu : 8
print(f"Bits lumineux de 10 (0b1010) : {compteur_bits_lumineux(10)}") # Attendu : 2
Défi 8 : Le Détecteur d’Intrusions dans le Tableau 🚨
Vous êtes le gardien d’un tableau de valeurs et vous devez vérifier si une valeur spécifique est présente à partir d’un certain point.
Exercice : Écrivez une fonction récursive detecteur_intrusions(valeur, tableau, indice_depart) qui renvoie True si valeur apparaît dans tableau à partir de indice_depart (inclus) jusqu’à la fin du tableau, et False sinon. On garantit que indice_depart est toujours un indice valide.
Prérequis : Maîtrise des listes/tableaux (accès par indice, len()), des opérateurs de comparaison et des booléens. Voir la Correction du Défi 8
Analyse du problème :
Cas de base 1 : Si indice_depart atteint la fin du tableau (len(tableau)), cela signifie que la valeur n’a pas été trouvée, donc on retourne False.
Cas de base 2 : Si la valeur à tableau[indice_depart] correspond à valeur, on a trouvé, on retourne True.
Cas récursif : Sinon, on continue la recherche à l’indice suivant (indice_depart + 1).
Code :
Python
def detecteur_intrusions(valeur, tableau, indice_depart):
"""
Vérifie si une valeur est présente dans un tableau à partir d'un certain indice.
valeur (any): La valeur à rechercher.
tableau (list): Le tableau dans lequel chercher.
indice_depart (int): L'indice à partir duquel commencer la recherche (inclus, >=0).
Retourne (bool): True si la valeur est trouvée, False sinon.
"""
# Cas de base 1 : L'indice a dépassé la fin du tableau, la valeur n'est pas trouvée.
if indice_depart == len(tableau):
return False
# Cas de base 2 : La valeur est trouvée à l'indice actuel.
elif tableau[indice_depart] == valeur:
return True
# Cas récursif : La valeur n'est pas à l'indice actuel, on cherche dans le reste du tableau.
else:
return detecteur_intrusions(valeur, tableau, indice_depart + 1)
# Tests rapides :
mon_tableau = [10, 20, 30, 40, 50]
print(f"20 dans [10, 20, 30, 40, 50] à partir de 0 : {detecteur_intrusions(20, mon_tableau, 0)}") # Attendu : True
print(f"60 dans [10, 20, 30, 40, 50] à partir de 0 : {detecteur_intrusions(60, mon_tableau, 0)}") # Attendu : False
print(f"40 dans [10, 20, 30, 40, 50] à partir de 3 : {detecteur_intrusions(40, mon_tableau, 3)}") # Attendu : True
print(f"10 dans [10, 20, 30, 40, 50] à partir de 1 : {detecteur_intrusions(10, mon_tableau, 1)}") # Attendu : False
print(f"50 dans [10, 20, 30, 40, 50] à partir de 4 : {detecteur_intrusions(50, mon_tableau, 4)}") # Attendu : True
Défi 9 : Le Secret du Triangle Magique de Pascal 🧙♂️
Le triangle de Pascal est un artefact mathématique où chaque nombre est la somme des deux nombres directement au-dessus de lui. Les bords du triangle sont toujours des 1.
Exercice :
Écrivez une fonction récursive coefficient_magique(n, p) qui renvoie la valeur du coefficient binomial C(n,p) (le nombre à la ligne n et à la position p dans le triangle de Pascal), en utilisant la définition récursive donnée :
C(n,p)=1 si p=0 ou n=p
C(n,p)=C(n−1,p−1)+C(n−1,p) sinon.
Utilisez une double boucle for pour afficher les 11 premières lignes (de n=0 à n=10) du triangle de Pascal, en utilisant votre fonction.
Prérequis : Maîtrise des boucles for imbriquées et de l’affichage formaté (print). Comprendre la définition mathématique récursive. Voir la Correction du Défi 9
Analyse du problème : La définition récursive est très claire :
Cas de base 1 : p = 0, le coefficient est 1.
Cas de base 2 : n = p, le coefficient est 1.
Cas récursif : C(n-1, p-1) + C(n-1, p).
Code :
Python
def coefficient_magique(n, p):
"""
Calcule le coefficient binomial C(n, p) du triangle de Pascal de manière récursive.
n (int): Le numéro de la ligne (>= 0).
p (int): La position dans la ligne (0 <= p <= n).
Retourne (int): La valeur du coefficient C(n, p).
"""
if p == 0 or n == p: # Cas de base : les bords du triangle
return 1
else: # Cas récursif : somme des deux éléments au-dessus
return coefficient_magique(n - 1, p - 1) + coefficient_magique(n - 1, p)
# Tests rapides de la fonction :
print(f"C(0, 0) : {coefficient_magique(0, 0)}") # Attendu : 1
print(f"C(3, 1) : {coefficient_magique(3, 1)}") # Attendu : 3
print(f"C(4, 2) : {coefficient_magique(4, 2)}") # Attendu : 6
# Dessin du triangle de Pascal
print("\n--- Triangle Magique de Pascal (jusqu'à n=10) ---")
for n_ligne in range(11): # Pour chaque ligne de 0 à 10
# Optionnel : pour centrer l'affichage (ajuster selon la taille de la console)
print(" " * (10 - n_ligne), end="")
for p_position in range(n_ligne + 1): # Pour chaque position dans la ligne
print(f"{coefficient_magique(n_ligne, p_position):4d}", end="") # :4d pour aligner
print() # Passer à la ligne suivante
Défi 10 : Retour sur les autres fractales
Faites une petite recherche sur les fractales de Sierpinsky.
Est ce que l’image fournie par l’IA est réaliste ? Etudier d’un peu plus près la logique derrière les deux fractales.
Exercice :
Créer deux programmes pour les deux versions de la fractale
Analyse du problème et conseils : on peut créer une fonction dessinant le motif de base : un triangle équilatéral / rectangle.
les coordonnées d’un triangle équilatéral de côté l et dont le premier sommet a pour coordonnées (0,0) seront (0,0) , (l,0) et (l/2,racine(3)/2).
pour le triangle de Sierpinski voici un début de programme :
from turtle import *
from math import sqrt
speed(0) # Vitesse maximale pour un dessin rapide
def triangle(x:int,y:int,l:int,c:str):
"""dessine un triangle équilatéral de dimension l et de couleur c
il aura une base horizontale et la pointe vers le haut"""
penup()
goto(x,y) # Position de départ pour le rectangle
pendown()
fillcolor(c)
begin_fill()
forward(l)
left(120)
forward(l)
left(120)
forward(l)
left(120)
end_fill()
def SierTri(x,y,l,c1,c2,n):
"""dessine le triangle de Sierpinski de dimension l à l'ordre n,
son premier sommet a pour coordonnées (x,y), c1 est la couleur majoritaire
c2 est celle des incrustations"""
if n==0 :
triangle(x,y,l,c1)
else :
triangle(x,y,l,c2) #l'incrustation apparaitra par transparence
SierTri(x,y,l/2,c1,c2,n-1)
SierTri(x+l/2,y,l/2,c1,c2,n-1)
SierTri(x+l/4,y+sqrt(3)*l/4,l/2,c1,c2,n-1)
def SierCent(l,c1,c2,n) :
SierTri(-l/2,-sqrt(3)*l/4,l,c1,c2,n)
SierCent(200,"blue","red",4)
done() # Garde la fenêtre ouverte
Pour le tapis, un peu moins d’aide est nécessaire,
from turtle import *
def rectangle(x,y,h,l,c):
penup()
goto(x,y) # Position de départ pour le rectangle
pendown()
fillcolor(c)
begin_fill()
forward(l)
right(90)
forward(h)
right(90)
forward(l)
right(90)
forward(h)
right(90)
end_fill()
def Sierpinsky(x,y,h,l,c1,c2,n):
if n==0 :
rectangle(x,y,h,l,c1)
else :
Sierpinsky(x,y,h/3,l/3,c1,c2,n-1)
Sierpinsky(x+l/3,y,h/3,l/3,c1,c2,n-1)
Sierpinsky(x+2*l/3,y,h/3,l/3,c1,c2,n-1)
Sierpinsky(x,y-h/3,h/3,l/3,c1,c2,n-1)
rectangle(x+l/3,y-h/3,h/3,l/3,c2)
Sierpinsky(x+2*l/3,y-h/3,h/3,l/3,c1,c2,n-1)
Sierpinsky(x,y-2*h/3,h/3,l/3,c1,c2,n-1)
Sierpinsky(x+l/3,y-2*h/3,h/3,l/3,c1,c2,n-1)
Sierpinsky(x+2*l/3,y-2*h/3,h/3,l/3,c1,c2,n-1)
speed(0) # Vitesse maximale pour un dessin rapide
Sierpinsky(-200,200,400,400,"blue","red",4)
done() # Garde la fenêtre ouverte
🚀 Étendre vos Horizons : Quand utiliser la Récursivité ?
disque sur un petit.
Mini-Application 2 : Le Déplaceur de Disques 💿
Recherchez les « Tours de Hanoï algorithme récursif » et essayez d’implémenter une fonction Python qui affiche les étapes pour déplacer les disques.
Python
def hanoi(n, source, cible, auxiliaire):
if n == 1:
print(f"Déplacer le disque 1 de {source} vers {cible}")
else:
hanoi(n - 1, source, auxiliaire, cible)
print(f"Déplacer le disque {n} de {source} vers {cible}")
hanoi(n - 1, auxiliaire, cible, source)
# Exemple : résoudre pour 3 disques
hanoi(3, "A", "C", "B")
ressources informatiques pour la formation et l’orientation :
Avenirs (la plateforme de l’Onisep, il y a pléthore pour les élèves comme pour leurs enseignants)
ParcourSup (utilisable dès la seconde, en se créant un compte on peut enregistrer les informations qui nous intéressent, on accède au moteur de recherche en clickant sur « se connecter » )
élection des délégués de classe (et de leur suppléant) : Sophie (Lilly), Valentin ( Maxime)
Début de la campagne PIX
Nom campagne : LPO Albert Einstein Parcours rentrée Terminale
Code : PSTPPJ998
Procédures pour les élèves ou les étudiants :
1 – Ils doivent passer par l’ENT (Ressources -> Médiacentre -> PIX)
2 – Ils doivent se « synchroniser » avec l’ENT à la première connexion, il peut arriver que certains se soient déjà connectés avec un autre moyen il leur sera demandé identifiant et mot de passe de cet autre moyen (mail, identifiant).
3 – Une fois sur PIX, ils saisissent le code de la campagne de rentrée de leur niveau.
4 – Ils suivent le parcours puis ils doivent envoyer leurs résultats à la fin.
si vous rencontrez des problèmes ou que vous avez des questions, contactez moi par pronote, je vous répondrai individuellement et je me servirai de l’échange anonymisé pour créer une notice, consultable sur le site.
jeudi 11 septembre
Jeudi 25 septembre vous aurez une heure de vie de classe dédiée à l’élection des délégués de classe et de l’éco délégué. Ces postes sont importants pour permettre une meilleure défense de vos intérêts lors des conseils de classe, mais aussi tout le long de l’année lors qu’il y aura des négociations avec la direction ou des élèves à soutenir. Etre délégué de classe c’est aussi avoir des possibilités de représenter tous les élèves pour certains votes.
Pour plus de clarté voici un petit récapitulatif des différentes instances où vous pouvez obtenir une représentation par un pair :
CVL (conseil de vie lycéenne) qui peut se présenter : n’importe qui qui peut voter : n’importe qui
Conseil d’administration : qui peut se présenter : les membres du CVL qui peut voter : les délégués de classe, les membres du CVL
Conseil de discipline : qui peut se présenter : les délégués de classe qui peut voter : les délégués de classe.
Bonne fin de semaine
Julien Kergot
PS : pour ceux qui ont envie de creuser le sujet vous trouverez ici le document qui a été partagé avec tous les professeurs principaux du lycée en préparations des élections.
la semaine prochaine, jeudi 11 (le jour J), vous allez passer votre certification PIX avec M. Moraru.
Pour que ça puisse se passer dans les meilleures conditions je tenais à vous rappeler quelques informations :
pour être certifiable il vous faut au moins 100points sur votre compte.
Pour que la séance soit gérable il faut que vous sachiez vous connecter à votre compte pix et que vous l’ayez fait avant le jour J.
sur pronote il est indiqué que ça se passera dans votre salle habituelle de philosophie, mais je pense que ça va sans doute changer.
Il est plus logique qu’ils vous mettent en H005 pour que vous puissiez accéder aux ordinateurs et au réseau du lycée.
Si vous voulez en savoir plus sur l’épreuve (modalités, difficulté), vous pouvez vous rapprocher de vos camarades de TG4 qui ont passé leur certifiction aujourd’hui avec M. Moraru)
Bonne soirée
Voici la procédure :
1 – Ils doivent passer par l’ENT (Ressources -> Médiacentre -> PIX)
2 – Ils doivent se « synchroniser » avec l’ENT à la première connexion, il peut arriver que certains se soient déjà connectés avec un autre moyen il leur sera demandé identifiant et mot de passe de cet autre moyen (mail, identifiant).
3 – Une fois sur PIX, ils saisissent le code de la campagne de rentrée de leur niveau. Nom campagne : LPO Albert Einstein Parcours rentrée Terminale Code : VYRPZD282
4 – Ils suivent le parcours puis ils doivent envoyer leurs résultats à la fin.
dimanche 23 Novembre
petit message pour les motivés, comme tous les ans les élèves sont invités à participer au concours général des lycéens.
Vous pouvez faire une ou plusieurs des épreuves de celui-ci (du moment qu’elles sont dans votre tronc général ou parmis vos options).
Si ça vous intéresse envoyez moi un message en MP et je vous apporterai un formulaire d’inscription lors de l’heure de vie de classe. Avant de le rendre rempli à madame Astier vous pouvez toujours en parler avec le professeur qui vous enseigne la matière concernée.
votre conseil de classe aura lieu le lundi 1er décembre à 18h. Jeudi 27 Novembre on fera l’heure de vie de classe dédiée à sa préparation. Vous êtes tous conviés.
dans un tout autre registre, le 25 novembre vous allez avoir une journée très particulière. Mme Roux et le groupe de professeurs investis dans l’égalité filles garçon ont organisé pour les élèves du lycée une série d’atelier portant sur les problématiques de harcélèment sexuel, de consentement … pour vous ça s’étalera sur la majeure partie de la journée. toutes les spés des élèves de terminale sautent le matin et donc vous commencerez votre journée à 10h à l’amphi accompagnés par Mme Delagrange avec un atelier nommé « stand up » qui se terminera à 11h30 de 14h à 16h vous aurez vos cours habituels et à 16h, vous trouverez monsieur Moraru au Foyer à côté de la cafétaria, où il fera l’appel avant de vous laisser faire l’atelier « consentement en milieu festif ».
Mardi 14 octobre
Bonsoir tout le monde,
la campagne d’inscription au bac a commencé hier.
A cette occasion, certaines personnes qui ne sont pas à jour dans leur dossier recevront un ou plusieurs messages mentionnant les pièces à amener rapidement à Mme Astier (secrétariat élève).
Pour tous les élèves de la classe, vous devez récupérer votre confirmation d’inscription et la vérifier, la corriger et me la retourner au plus tard le jour de la rentrée.
1ère phase : récupération du document
j’assurerai une permanence spécialement pour vous en salle H009 demain de 10h à 12h, je vous donnerai VOTRE confirmation et vous ferai émarger (preuve que je vous ai bien remis en main propre le document). ça vous prendra deux minutes, mais c’est essentiel que ça soit fait ce jour là et sur ce créneau. En cas d’oubli il vous faudra me courir après pour avoir le document avant qu’on parte tous en congé.
2ème phase : relecture , correction
vous relisez chacune des information et corrigez au stylo rouge celles qui ne sont pas justes.
S’il y a une erreur sur le papier, il y en a aussi une sur les serveurs. Il vous faudra donc vous connecter à l’application Cyclades, et faire votre correction à cet endroit là aussi.
3ème phase : rendu du document corrigé
je m’arrangerai avec Mme Rodriguez pour qu’elle les récupère le lund de la rentrée lors de son cours.
bonne soirée
PS : si vous arrivez d’une autre autre académie il vous faudra fournir votre relevé de note de première à Mme Astier.
Lundi 29 septembre
Bonjour tout le monde,
pour aider au mieux les élèves ayant du mal à s’orrienter, la direction a décidé de fixer les EPO un peu plus tôt cette année. Ces rendez vous réuniront mme Roux, une psy EN du CIO, Mme Ravidat (votre CPE) et moi même d’un côté de la table, vous et au moins un de vos responsables légaux de l’autre. Cette entretien durera 30 min.
Vu que c’est assez compliqué et chronophage pour les différents intervenants, l’année dernière on octroyait autour de 5 rendez vous par classe, or d’après vos questionnaires de rentrée j’ai repéré 8 personnes qui pourraient en bénéficier… si toutes ces personnes en ont vraiment besoin on fera notre possible pour les recevoir, toutefois, ce rendez vous ne se substitue pas à une recherche personnelle. Il est donc super important que toutes les personnes qui se sentent en difficultés commencent par prendre un rendez vous avec le CIO et aussi rencontrer Mme Ravidat qui a des ressources. (cinq des huit repérés sont déjà passé la voir : félicitations pour votre sérieux !!!)
Toujours pour préparer l’orientation, je vous conseille à tous de passer voir https://dossier.parcoursup.fr/Candidat/carte , pour commencer à repérer les écoles et les formations pour l’année prochaine.
Pour ce qui est de l’heure de 16h à 17h le jeudi :
* le créneau proposé pour déplacer l’heure d’EMC n’est pas valide, donc voyez avec votre prof de philo s’il a des solutions à vous proposer.
* je viens de réaliser que ma disponibilité du mercredi est trop aléatoire (j’ai des fois des apprentis du CFA sur ce créneau) pour permettre un changement durable, celui ci ne pourra être que ponctuel. Toutes mes excuses pour ne pas avoir vu le problème plutôt.
Pour la vie de classe, comme prévu il ne nous reste que trois heures obligatoires pour préparer les 3 conseils de classes. Toutes les autres seront posées pour vous aider à gérer des problèmes spécifiques, généralement l’orientation. Suivant le nombre d’élève on aura sans doute plus de possiblité pour trouver un créneau plaisant.
Pas de vie de classe cette semaine. La prochaine sera mercredi 5 octobre à 11h en H012. Pas d’obligations, je prendrai ceux qui ont des difficultés avec PIX, ou avec l’orientation/parcoursup.
Il y a des chances pour qu’elle n’apparaisse pas sur l’agenda pronote. En cas de problème ou de changement de salle ça se fera sur ce fil.
Bonne semaine
Vous êtes arrivé(e) à la fin du message ! Merci pour votre patience et votre ténacité.
semaine du 22 septembre
Voici le résultat des élections des délégués de classe (et de leurs suppléants) : Sarah (Célia T.) , Naji (Samuel)
Voici le résultat des élections de l’éco-délégué de classe (et de sa suppléante) : Sara (Anissa)
Début de la campagne PIX (certification entre le 3 novembre et le 6 mars)
Nom campagne : LPO Albert Einstein Parcours rentrée Terminale
Code : VYRPZD282
Procédures pour les élèves ou les étudiants :
1 – Ils doivent passer par l’ENT (Ressources -> Médiacentre -> PIX)
2 – Ils doivent se « synchroniser » avec l’ENT à la première connexion, il peut arriver que certains se soient déjà connectés avec un autre moyen il leur sera demandé identifiant et mot de passe de cet autre moyen (mail, identifiant).
3 – Une fois sur PIX, ils saisissent le code de la campagne de rentrée de leur niveau.
4 – Ils suivent le parcours puis ils doivent envoyer leurs résultats à la fin.
si vous rencontrez des problèmes ou que vous avez des questions, contactez moi par pronote, je vous répondrai individuellement et je me servirai de l’échange anonymisé pour créer une notice, consultable sur le site.
jeudi 11 septembre
La semaine prochaine, jeudi 18 septembre, vous aurez une heure de vie de classe dédiée à l’élection des délégués de classe et de l’éco délégué. Ces postes sont importants pour permettre une meilleure défense de vos intérêts lors des conseils de classe, mais aussi tout le long de l’année lors qu’il y aura des négociations avec la direction ou des élèves à soutenir. Etre délégué de classe c’est aussi avoir des possibilités de représenter tous les élèves pour certains votes.
Pour plus de clarté voici un petit récapitulatif des différentes instances où vous pouvez obtenir une représentation par un pair :
CVL (conseil de vie lycéenne) qui peut se présenter : n’importe qui qui peut voter : n’importe qui
Conseil d’administration : qui peut se présenter : les membres du CVL qui peut voter : les délégués de classe, les membres du CVL
Conseil de discipline : qui peut se présenter : les délégués de classe qui peut voter : les délégués de classe.
Bonne fin de semaine
Julien Kergot
PS : pour ceux qui ont envie de creuser le sujet vous trouverez ici le document qui a été partagé avec tous les professeurs principaux du lycée en préparations des élections.
Mme Horn : pour les élèves qui ont la spécialité PC et la spécialité SVT les cours débutant l’après-midi à 14h, les élèves auront exceptionnellement demain 1h30 de TP PC ou SVT : 14h-15h30 au lieu de 13-15h // 15h30-17h au lieu de 15h-17h.
ajouts post heures de vie de classe :
J’ai fait une erreur d’interprétation quand j’ai lu les calendriers des photos et de la remise des livres. J’ai cru que les deux feuilles faisaient références aux photos, donc la date annoncée le mardi 9 septembre à 15h30 avec Mme Roques est juste sauf qu’elle correspond à la distribution des livres. Pour les photos par contre ça sera le lundi 8 septembre à 11h avec Mme Rodriguez.
livret d’accueil (nom des intervenants et moyen de les contacter)
petit simulateur pour prévoir votre mention au bac (en attendant d’avoir les résultats aux épreuves vous pouvez utiliser vos moyenne pour pouvoir prévoir).
Bonjour à toutes et à tous ! 🤩 Aujourd’hui, on va explorer un sujet super cool et très utile en informatique : les arbres binaires et l’arborescence ! Accrochez-vous, ça va être clair, amusant et vous allez voir que c’est partout autour de nous !
🏉 Le tournoi de rugby : une histoire d’arbres !
Imaginez que vous êtes l’organisateur d’un grand tournoi de rugby. Au début, tout est simple : 4 poules de 4 équipes, et les 2 meilleures de chaque poule se qualifient pour les quarts de finale. Jusque-là, tout va bien ! Mais quand il faut expliquer aux spectateurs comment on passe des quarts aux demies, et des demies à la finale, c’est la panique générale ! 🤯
Voici les équipes qualifiées :
Poule 1 : 1er Eq1 ; 2e Eq8
Poule 2 : 1er Eq2 ; 2e Eq7
Poule 3 : 1er Eq3 ; 2e Eq6
Poule 4 : 1er Eq4 ; 2e Eq5
Les quarts de finale sont :
Quart 1 : Eq1 contre Eq5
Quart 2 : Eq2 contre Eq6
Quart 3 : Eq3 contre Eq7
Quart 4 : Eq4 contre Eq8
Et les demi-finales :
Demi-finale 1 : Vainqueur Quart 1 contre Vainqueur Quart 3
Demi-finale 2 : Vainqueur Quart 2 contre Vainqueur Quart 4
C’est là que les choses se compliquent ! Pour un spectateur lambda, c’est un vrai casse-tête de suivre tout ça. Et si on utilisait un graphique ? Un truc simple qui montre qui joue contre qui, et comment on arrive à la finale ?
Bingo ! Ce type de graphique, c’est ce qu’on appelle une structure en arbre ! Ça simplifie énormément la compréhension des liens hiérarchiques. Les spectateurs peuvent facilement visualiser le chemin vers la gloire ! 🏆
🌳 Mais qu’est-ce qu’un arbre en informatique ?
Vous avez déjà croisé des arbres sans le savoir ! Pensez à un arbre généalogique : vous êtes un « fils » de vos parents, qui sont eux-mêmes les « fils » de leurs parents, et ainsi de suite. C’est une structure hiérarchique parfaite !
Un autre exemple que vous avez vu l’année dernière : les systèmes de fichiers de votre ordinateur (comme sur Linux ou macOS). Vous avez un dossier principal (la « racine »), et à l’intérieur, d’autres dossiers et fichiers. Certains sont plus « profonds » que d’autres. On ne peut pas représenter cette hiérarchie juste avec une simple liste de noms !
Les arbres sont des structures de données super puissantes et très utilisées en informatique parce qu’elles permettent d’organiser des informations de manière hiérarchique. Ça veut dire qu’il y a des relations de « parent-enfant » ou de « supérieur-inférieur » entre les données. Parfois, il y a une notion de temps (comme pour le tournoi : les quarts avant les demies), mais ce n’est pas toujours le cas (le système de fichiers n’a pas de dimension temporelle).
🌲 Les arbres binaires : la version VIP des arbres !
Dans le grand monde des arbres, il y a une catégorie très spéciale et très populaire : les arbres binaires. Notre arbre de tournoi de rugby est un arbre binaire, et l’arbre « père, mère… » aussi. Par contre, le système de fichiers n’en est pas un.
Alors, quelle est la règle d’or d’un arbre binaire ? C’est simple : chaque élément (appelé « nœud ») peut avoir au maximum DEUX branches qui partent de lui. Pas plus ! Dans notre système de fichiers, la racine a beaucoup plus que deux branches qui partent d’elle, donc ce n’est pas un arbre binaire.
Dans la suite, on va se concentrer uniquement sur ces stars : les arbres binaires !
🗣️ Le dico de l’arbre binaire : du vocabulaire à connaître !
Pour ne pas se perdre, voici un petit glossaire des termes clés quand on parle d’arbres binaires. Regardons cet arbre ensemble :
Nœud : C’est un élément de l’arbre. Pensez à chaque bulle dans notre schéma (A, B, C, D, etc.) comme un nœud. C’est l’unité de base de notre arbre.
Racine : C’est le tout premier nœud de l’arbre, celui par où tout commence. C’est un peu le « chef » de l’arbre ! Dans notre exemple, c’est le nœud A.
Fils : Si un nœud a des éléments qui partent de lui, ce sont ses « fils ». Par exemple, les nœuds E et D sont les fils du nœud B.
Père : Le contraire de fils ! Le nœud B est le père des nœuds E et D. Chaque nœud (sauf la racine) a un seul père.
Feuille : Un nœud qui n’a aucun fils. C’est la fin du chemin pour ce nœud ! Dans notre exemple, D, H, N, O, J, K, L, P et Q sont des feuilles. Ils n’ont personne « en dessous » d’eux.
Sous-arbre : À partir d’un nœud (qui n’est pas une feuille), on peut imaginer un « mini-arbre » formé par ce nœud et tous ses descendants. Dans un arbre binaire, on parle de sous-arbre gauche et de sous-arbre droit. Par exemple, à partir de C, le sous-arbre gauche contient F, J et K, et le sous-arbre droit contient G, L, M, P et Q.
Arête : C’est le trait qui relie deux nœuds. C’est le « chemin » entre eux.
Taille d’un arbre : C’est tout simplement le nombre total de nœuds qu’il contient. Comptez-les tous !
Profondeur d’un nœud : C’est la distance entre la racine et ce nœud. On compte le nombre de nœuds sur le chemin.
Attention : Parfois, la racine est à la profondeur 1, parfois à 0. C’est une convention ! Dans ce cours, on va dire que la profondeur de la racine est 1. Donc, si la racine est à 1, un nœud juste en dessous (ses fils) sera à 2, et ainsi de suite.
Exemples (avec racine à profondeur 1) : profondeur de B = 2 ; profondeur de I = 4 ; profondeur de P = 5.
Hauteur d’un arbre : C’est la plus grande profondeur parmi tous les nœuds de l’arbre. En gros, c’est la profondeur de la feuille la plus « basse » de l’arbre.
Avec notre convention (racine à profondeur 1), la hauteur de notre arbre est 5 (car P est à la profondeur 5).
🔄 Les arbres sont des structures récursives !
C’est un point super important : les arbres sont comme des poupées russes ! Un nœud, avec ses sous-arbres gauche et droit, peut être vu comme un arbre en lui-même. Et ces sous-arbres sont eux-mêmes des arbres, et ainsi de suite jusqu’aux feuilles. Cette idée de « structure qui contient des structures du même type » est la base de la récursivité, un concept clé en informatique.
🎨 Des arbres de toutes les formes !
On peut avoir des arbres de même taille qui ont des formes très différentes. Regardez ces deux exemples :
L’arbre 1 est dit « filiforme » (ou dégénéré). Il ressemble à une longue chaîne. C’est un peu le « serpent » des arbres !
L’arbre 2 est dit « complet« . Tous ses nœuds, sauf les feuilles, ont deux fils, et toutes les feuilles sont à la même profondeur. C’est un peu le « buisson » bien taillé ! 🌳
On dit que l’arbre 1 est déséquilibré et l’arbre 2 est équilibré. L’équilibre est important pour l’efficacité de certains algorithmes, comme on le verra.
Quelques maths pour les pros ! 🤓
Pour un arbre filiforme de taille n, sa hauteur h est n−1 (si on considère que la racine est à profondeur 0).
Pour un arbre complet de taille n, sa hauteur h est lfloorlog_2(n)rfloor (la partie entière de log_2(n)). Pour l’arbre 2 (taille 7), log_2(7)approx2.8, donc sa hauteur est 2.
Pour n’importe quel arbre binaire de taille n et de hauteur h, on a toujours : lfloorlog_2(n)rfloorlehlen−1.
🧑💻 Arbres binaires en Python : on va les construire !
Python ne propose pas d’arbres binaires « prêts à l’emploi », mais pas de panique ! Plus tard dans l’année, nous allons apprendre à les implémenter nous-mêmes en utilisant la programmation orientée objet. C’est un excellent moyen de comprendre comment ça marche « sous le capot » ! 🛠️
🚀 Les algorithmes sur les arbres binaires : L’aventure continue !
Maintenant que nous maîtrisons le vocabulaire, il est temps de passer à l’action ! Comment manipuler ces arbres ? On va découvrir des algorithmes super utiles.
Chaque nœud d’un arbre binaire a :
Une clé (ou valeur) : c’est l’information qu’il contient.
Un sous-arbre gauche : le « mini-arbre » de gauche.
Un sous-arbre droit : le « mini-arbre » de droite.
Regardons cet arbre :
Pour le nœud A (la racine) :
Son sous-arbre gauche contient B, C, D, E.
Son sous-arbre droit contient F, G, H, I, J.
Pour le nœud B :
Son sous-arbre gauche contient C, E.
Son sous-arbre droit contient D.
Un arbre (ou un sous-arbre) vide est représenté par NIL (du latin nihil, qui veut dire « rien »). Si on prend le nœud G :
Son sous-arbre gauche contient I.
Son sous-arbre droit est vide (NIL).
Retenez bien : un sous-arbre, même s’il n’a qu’un seul nœud ou qu’il est vide, est toujours considéré comme un arbre !
En général, pour un arbre T et un nœud x :
T.racine : c’est le nœud racine de l’arbre T.
x.gauche : c’est le sous-arbre gauche du nœud x.
x.droit : c’est le sous-arbre droit du nœud x.
x.clé : c’est la valeur stockée dans le nœud x.
Et si un nœud x est une feuille, alors x.gauche et x.droit sont des arbres vides (NIL).
📏 Calculer la hauteur d’un arbre : l’algorithme magique !
On se souvient de la hauteur ? C’est la profondeur maximale ! Comment la calculer de manière automatique ? Voici un algorithme récursif :
VARIABLE
T : arbre
x : noeud
DEBUT
HAUTEUR(T) :
si T ≠ NIL : // Si l'arbre n'est pas vide
x ← T.racine // On prend le noeud racine
// La hauteur est 1 (pour le noeud actuel) + le max des hauteurs de ses sous-arbres
renvoyer 1 + max(HAUTEUR(x.gauche), HAUTEUR(x.droit))
sinon : // Si l'arbre est vide
renvoyer 0
fin si
FIN
À faire vous-même 1 Prenez l’arbre ci-dessus et essayez d’appliquer cet algorithme « à la main » ! C’est un super exercice pour comprendre la récursivité en action. N’hésitez pas à dessiner les étapes sur un brouillon. Si vous êtes bloqués, c’est normal, la récursivité peut être un peu tricky au début ! 😉
🔢 Calculer la taille d’un arbre : compter les nœuds !
On veut maintenant savoir combien de nœuds il y a dans un arbre. C’est très similaire au calcul de la hauteur !
VARIABLE
T : arbre
x : noeud
DEBUT
TAILLE(T) :
si T ≠ NIL : // Si l'arbre n'est pas vide
x ← T.racine // On prend le noeud racine
// La taille est 1 (pour le noeud actuel) + la taille du sous-arbre gauche + la taille du sous-arbre droit
renvoyer 1 + TAILLE(x.gauche) + TAILLE(x.droit)
sinon : // Si l'arbre est vide
renvoyer 0
fin si
FIN
À faire vous-même 2 Appliquez cet algorithme sur l’arbre ci-dessus. Vous devriez le trouver un peu plus simple que le précédent !
🚶 Parcourir un arbre : faire le tour du propriétaire !
Parcourir un arbre, ça veut dire visiter tous ses nœuds, mais dans un ordre bien précis. Il existe plusieurs façons de faire ce « tour du propriétaire ». On va en explorer quelques-unes.
Parcours infixe (ou en « ordre central »)
Cet algorithme visite d’abord le sous-arbre gauche, puis le nœud actuel, puis le sous-arbre droit. C’est comme une visite guidée équilibrée !
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-INFIXE(T) :
si T ≠ NIL :
x ← T.racine
PARCOURS-INFIXE(x.gauche) // Visite le sous-arbre gauche
affiche x.clé // Affiche la clé du noeud actuel
PARCOURS-INFIXE(x.droit) // Visite le sous-arbre droit
fin si
FIN
À faire vous-même 3 Vérifiez qu’en appliquant cet algorithme sur l’arbre ci-dessus, l’ordre d’affichage est bien : C, E, B, D, A, I, G, F, H, J.
Parcours préfixe (ou en « ordre de profondeur »)
Ici, on visite d’abord le nœud actuel, puis le sous-arbre gauche, puis le sous-arbre droit. On « affiche » avant d’explorer !
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-PREFIXE(T) :
si T ≠ NIL :
x ← T.racine
affiche x.clé // Affiche la clé du noeud actuel
PARCOURS-PREFIXE(x.gauche) // Visite le sous-arbre gauche
PARCOURS-PREFIXE(x.droit) // Visite le sous-arbre droit
fin si
FIN
À faire vous-même 4 Vérifiez qu’en appliquant cet algorithme sur l’arbre ci-dessus, l’ordre d’affichage est bien : A, B, C, E, D, F, G, I, H, J.
Parcours suffixe (ou en « ordre postfixe »)
Pour ce parcours, on visite d’abord le sous-arbre gauche, puis le sous-arbre droit, et enfin le nœud actuel. On « affiche » à la fin de l’exploration !
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-SUFFIXE(T) :
si T ≠ NIL :
x ← T.racine
PARCOURS-SUFFIXE(x.gauche) // Visite le sous-arbre gauche
PARCOURS-SUFFIXE(x.droit) // Visite le sous-arbre droit
affiche x.clé // Affiche la clé du noeud actuel
fin si
FIN
À faire vous-même 5 Vérifiez qu’en appliquant cet algorithme sur l’arbre ci-dessus, l’ordre d’affichage est bien : E, C, D, B, I, G, J, H, F, A.
Parcourir un arbre en largeur d’abord
Contrairement aux parcours précédents (qui explorent en profondeur), celui-ci explore niveau par niveau, de gauche à droite. Il utilise une structure de données que vous connaissez : la file (FIFO) !
VARIABLE
T : arbre
Tg : arbre
Td : arbre
x : noeud
f : file (initialement vide)
DEBUT
PARCOURS-LARGEUR(T) :
enfiler(T.racine, f) // On place la racine dans la file
tant que f non vide :
x ← defiler(f) // On retire le premier élément de la file
affiche x.clé // On l'affiche
si x.gauche ≠ NIL :
Tg ← x.gauche
enfiler(Tg.racine, f) // On ajoute le fils gauche à la file
fin si
si x.droit ≠ NIL :
Td ← x.droit
enfiler(Td.racine, f) // On ajoute le fils droit à la file
fin si
fin tant que
FIN
À faire vous-même 6 Vérifiez qu’en appliquant cet algorithme sur l’arbre ci-dessus, l’ordre d’affichage est bien : A, B, F, C, D, G, H, E, I, J.
Pourquoi parle-t-on de parcours en largeur ? Parce qu’on explore tous les nœuds d’un même niveau (ou « largeur ») avant de passer au niveau suivant. Pensez à une inondation qui se répand !
🕵️ Arbre binaire de recherche : le détective des données !
Un arbre binaire de recherche (ABR) est un type particulier d’arbre binaire, très très utile ! C’est comme un arbre binaire qui a le sens de l’ordre. Pour qu’un arbre soit un ABR, il faut trois choses :
C’est un arbre binaire (logique !).
Les clés des nœuds doivent pouvoir être ordonnées (on peut les comparer : « plus petit que », « plus grand que »). Imaginez des nombres ou des mots dans l’ordre alphabétique.
La règle d’or : pour n’importe quel nœud x :
Si un nœud y est dans son sous-arbre gauche, alors y.clé doit être inférieure ou égale à x.clé.
Si un nœud y est dans son sous-arbre droit, alors x.clé doit être inférieure ou égale à y.clé.
À faire vous-même 7 Vérifiez que l’arbre ci-dessus est bien un arbre binaire de recherche. Prenez quelques nœuds au hasard et vérifiez la règle !
À faire vous-même 8 Appliquez l’algorithme de parcours infixe (qu’on a vu plus haut) sur l’arbre binaire de recherche ci-dessus. Que remarquez-vous sur l’ordre des clés affichées ? Indice : c’est magique ! ✨
🔍 Recherche d’une clé dans un ABR : plus rapide que l’éclair !
Grâce à la propriété d’ordre des ABR, on peut chercher une clé très efficacement ! C’est un peu comme la recherche dichotomique que vous avez étudiée l’année dernière, mais pour les arbres !
Voici l’algorithme de recherche (version récursive) :
VARIABLE
T : arbre
x : noeud
k : entier // La clé que l'on cherche
DEBUT
ARBRE-RECHERCHE(T,k) :
si T == NIL : // Si l'arbre est vide, la clé n'y est pas
renvoyer faux
fin si
x ← T.racine // On prend le noeud racine
si k == x.clé : // Si la clé est celle du noeud actuel, on l'a trouvée !
renvoyer vrai
fin si
si k < x.clé : // Si la clé recherchée est plus petite, on va à gauche
renvoyer ARBRE-RECHERCHE(x.gauche,k)
sinon : // Sinon (si elle est plus grande), on va à droite
renvoyer ARBRE-RECHERCHE(x.droit,k)
fin si
FIN
À faire vous-même 9 Étudiez attentivement cet algorithme. Il est un peu le couteau suisse des ABR !
À faire vous-même 10 Appliquez l’algorithme ARBRE-RECHERCHE sur l’arbre ci-dessus. On va chercher la clé k = 13. Tracez le chemin !
À faire vous-même 11 Appliquez l’algorithme ARBRE-RECHERCHE sur l’arbre ci-dessus. On va chercher la clé k = 16. Que se passe-t-il ?
L’efficacité de la recherche
Si l’ABR est équilibré (comme notre « buisson » !), la recherche est super rapide : sa complexité est en O(log_2(n)). C’est comme la dichotomie !
Si l’ABR est filiforme (comme notre « serpent » !), la recherche est moins rapide : sa complexité est en O(n). C’est comme une recherche linéaire dans une liste.
Un O(log_2(n)) est beaucoup plus efficace qu’un O(n) pour les grandes quantités de données ! C’est pourquoi on essaie souvent d’avoir des ABR équilibrés.
Version itérative de la recherche
On peut aussi faire la recherche sans récursion, avec une boucle tant que :
VARIABLE
T : arbre
x : noeud
k : entier
DEBUT
ARBRE-RECHERCHE_ITE(T,k) :
x ← T.racine
tant que T ≠ NIL et k ≠ x.clé : // Tant que l'arbre n'est pas vide ET qu'on n'a pas trouvé la clé
x ← T.racine // IMPORTANT : on doit mettre à jour x AVANT de modifier T
si k < x.clé :
T ← x.gauche // On se déplace vers le sous-arbre gauche
sinon :
T ← x.droit // On se déplace vers le sous-arbre droit
fin si
fin tant que
si k == x.clé : // Si on est sorti de la boucle parce qu'on a trouvé la clé
renvoyer vrai
sinon : // Sinon, c'est qu'on est tombé sur un NIL, la clé n'est pas là
renvoyer faux
fin si
FIN
À faire vous-même 12 Étudiez cet algorithme. Comment se compare-t-il à la version récursive ?
➕ Insertion d’une clé dans un ABR : ajouter une branche !
On peut aussi ajouter de nouveaux nœuds à un ABR, tout en respectant ses règles strictes !
VARIABLE
T : arbre
x : noeud
y : noeud // Le nouveau noeud à insérer
DEBUT
ARBRE-INSERTION(T,y) :
x ← T.racine // On commence par la racine
tant que T ≠ NIL : // On parcourt l'arbre jusqu'à trouver l'endroit où insérer
x ← T.racine // IMPORTANT : on doit mettre à jour x AVANT de modifier T
si y.clé < x.clé :
T ← x.gauche // Si la clé à insérer est plus petite, on va à gauche
sinon :
T ← x.droit // Sinon, on va à droite
fin si
fin tant que
// On est sorti de la boucle, T est NIL. x est le parent potentiel du nouveau noeud.
si y.clé < x.clé : // Si la clé à insérer est plus petite que celle du parent
insérer y à gauche de x // On l'insère comme fils gauche
sinon : // Sinon (si elle est plus grande)
insérer y à droite de x // On l'insère comme fils droit
fin si
FIN
À faire vous-même 13 Étudiez attentivement cet algorithme. Il montre comment maintenir l’ordre d’un ABR lors d’une insertion.
À faire vous-même 14 Appliquez l’algorithme ARBRE-INSERTION sur l’arbre ci-dessus. On va insérer un nouveau nœud avec la clé y.clé = 16. Où va-t-il se placer ?
Voilà, vous avez maintenant toutes les bases pour comprendre les arbres binaires et l’arborescence ! C’est une structure fondamentale en informatique, qui sert à organiser des données de manière efficace. Des tournois de rugby aux fichiers de votre ordinateur, les arbres sont partout !
💾 XML et JSON : les langages secrets du web (et des données) !
Vous avez vu comment les arbres nous aident à organiser des données de manière hiérarchique. Eh bien, dans le monde réel de l’informatique, il y a des formats super populaires qui utilisent cette idée pour échanger des données entre différentes applications, ou pour stocker des informations. Ce sont le XML et le JSON ! Ils sont un peu comme les « langages secrets » que les ordinateurs utilisent pour se parler et se comprendre.
Imaginez que vous êtes un chef et que vous voulez envoyer la recette de votre plat le plus incroyable à un ami. Vous ne pouvez pas juste lui envoyer une image, il a besoin des ingrédients, des quantités, des étapes… Bref, des données structurées ! XML et JSON sont ces « formats de recette » super précis.
📝 XML : l’ancêtre bavard des balises
Le XML (pour eXtensible Markup Language) est un peu le grand-père des formats d’échange de données. Il est né pour être très précis, très formel, et on le reconnaît tout de suite à ses balises !
Pensez aux balises HTML que vous avez peut-être déjà vues (<p>, <h1>, <img>). XML, c’est le même principe, mais vous pouvez inventer vos propres balises ! C’est ce qui le rend « extensible ».
Voici à quoi ressemble notre recette de grand chef en XML :
XML
<recette>
<nom>Gâteau au chocolat super gourmand</nom>
<temps_preparation unite="minutes">15</temps_preparation>
<temps_cuisson unite="minutes">30</tempssson>
<ingredients>
<ingredient>
<nom>Chocolat noir</nom>
<quantite unite="grammes">200</quantite>
</ingredient>
<ingredient>
<nom>Farine</nom>
<quantite unite="grammes">100</quantite>
</ingredient>
<ingredient>
<nom>Oeufs</nom>
<quantite unite="unités">4</quantite>
</ingredient>
</ingredients>
<etapes>
<etape numero="1">Faire fondre le chocolat.</etape>
<etape numero="2">Mélanger les œufs et la farine.</etape>
<etape numero="3">Incorporer le chocolat fondu.</etape>
</etapes>
</recette>
Ce qu’il faut retenir du XML :
Hiérarchique comme un arbre : Chaque balise (<recette>, <ingredients>, <ingredient>) peut contenir d’autres balises, créant une structure en arbre ! C’est comme les nœuds et les sous-arbres que nous avons vus.
Balises de début et de fin : Pour chaque élément, vous avez une balise d’ouverture (<nom>) et une balise de fermeture (</nom>). C’est ce qui le rend verbeux (il y a beaucoup de caractères).
Attributs : On peut ajouter des informations directement sur les balises (comme unite="minutes" pour temps_preparation).
Lisible par l’humain : Même si c’est un peu long, on comprend ce que ça veut dire.
Strict : Il y a des règles très précises à respecter pour que le XML soit « bien formé » (par exemple, pas de balise oubliée).
Le XML est encore très utilisé, surtout dans les systèmes d’entreprise où la validation des données est primordiale.
🚀 JSON : le petit nouveau léger et agile
Le JSON (pour JavaScript Object Notation) est arrivé plus tard et a gagné en popularité grâce à sa simplicité et sa légèreté. Il est devenu le chouchou du web et des applications mobiles pour échanger des données. Il est inspiré de la façon dont les objets sont structurés en JavaScript, mais il est universel.
Objets : des paires « clé-valeur » entourées d’accolades {}. Les clés sont des chaînes de caractères (entre guillemets) et les valeurs peuvent être des nombres, des chaînes de caractères, des booléens, null, d’autres objets ou des tableaux. C’est l’équivalent des nœuds avec des attributs en XML.
Tableaux (ou listes) : des collections de valeurs ordonnées, entourées de crochets []. C’est l’équivalent d’une liste d’éléments similaires (comme nos ingrédients ou nos étapes).
Moins verbeux que le XML : Moins de caractères à écrire, ce qui est pratique pour la vitesse de transmission des données.
Très populaire : C’est le format le plus courant pour les API web (Application Programming Interface), c’est-à-dire quand des applications communiquent entre elles sur Internet.
Facile à analyser (parser) : Les langages de programmation (comme Python !) ont des outils intégrés qui rendent très facile la lecture et l’écriture de JSON.
Le JSON, avec sa simplicité et sa légèreté, est devenu le roi de l’échange de données sur le web.
🆚 XML vs JSON : qui gagne le match ?
Ce n’est pas vraiment une compétition, ils ont tous les deux leurs points forts !
Caractéristique
XML
JSON
Philosophie
Langage de balisage extensible
Notation d’objets pour JavaScript (mais universel)
Syntaxe
Balises <element> et </element>
{} pour objets, [] pour tableaux
Lisibilité
Très lisible, mais verbeux
Très lisible, plus concis
Taille des fichiers
Généralement plus grands
Généralement plus petits
Utilisation typique
Configuration, documents complexes, SOAP
API web, applications mobiles, NoSQL
Modèle de données
Arbre hiérarchique
Paires clé-valeur et tableaux
Exporter vers Sheets
En gros, les deux formats permettent de représenter des données structurées sous forme hiérarchique, exactement comme un arbre ! Le choix entre l’un ou l’autre dépend souvent du contexte et des exigences du projet. Pour la NSI, il est important de connaître les deux car ils illustrent parfaitement l’importance de l’arborescence dans l’organisation des données.
Et voilà, vous êtes maintenant incollables sur les formats XML et JSON, et vous comprenez mieux leur lien avec les arbres
Les défis des arbres binaires et des données structurées !
Exercice 1 : Les Arbres Bâtisseurs 🌳
Le défi : Dessiner toutes les formes possibles d’arbres binaires pour un nombre donné de nœuds. C’est comme être un architecte d’arbres !
Prérequis :
Comprendre la définition d’un arbre binaire (chaque nœud a au maximum deux fils).
Savoir ce qu’est un nœud.
Consignes : Dessine tous les arbres binaires différents qui ont :
3 nœuds
4 nœuds
Indice : La forme compte ! Deux arbres sont différents si leur structure n’est pas la même, même si les nœuds n’ont pas de noms spécifiques.
Solution :
Pour 3 nœuds (il y en a 5) :
Le « peigne » à gauche : Nœud central, un fils gauche, et ce fils gauche a un autre fils gauche.
Le « peigne » à droite : Nœud central, un fils droit, et ce fils droit a un autre fils droit.
La « branche » gauche et droite : Nœud central, un fils gauche, et ce fils gauche a un fils droit.
La « branche » droite et gauche : Nœud central, un fils droit, et ce fils droit a un fils gauche.
L’arbre « complet » (ou presque) : Nœud central, un fils gauche, un fils droit.
Pour 4 nœuds (il y en a 14) : C’est un peu plus complexe ! Les 5 formes de 3 nœuds peuvent être étendues de diverses manières. Pensez aux variations en ajoutant le quatrième nœud comme fils gauche ou droit d’une feuille existante, ou en transformant une feuille en nœud interne.
Exercice 2 : La Pyramide de Catalan 🔢
Le défi : Sans les dessiner tous, deviner combien d’arbres binaires différents on peut construire avec 5 nœuds. C’est un peu comme une énigme mathématique !
Prérequis :
Aucun prérequis spécifique en dehors de la logique. C’est un exercice de reconnaissance de suite !
Informations données :
0 nœud : 1 arbre (l’arbre vide)
1 nœud : 1 arbre
2 nœuds : 2 arbres
3 nœuds : 5 arbres
4 nœuds : 14 arbres
Consignes : Calcule le nombre d’arbres binaires différents contenant 5 nœuds.
Solution : Cette suite est célèbre en mathématiques ! Il s’agit des nombres de Catalan. Pour trouver le nombre d’arbres binaires distincts avec n nœuds, on utilise la formule C_n=frac1n+1binom2nn.
Pour n=0, C_0=frac11binom00=1times1=1
Pour n=1, C_1=frac12binom21=frac12times2=1
Pour n=2, C_2=frac13binom42=frac13times6=2
Pour n=3, C_3=frac14binom63=frac14times20=5
Pour n=4, C_4=frac15binom84=frac15times70=14
Pour n=5, on calcule : C_5=frac15+1binom2times55=frac16binom105
Il y a donc 42 arbres binaires différents contenant 5 nœuds !
Exercice 3 : L’Imprimeur d’Arbres Fous 🤯
Le défi : Écrire un algorithme qui affiche un arbre binaire d’une manière très spécifique, en utilisant des parenthèses. C’est comme traduire l’arbre en un langage mathématique !
Prérequis :
Comprendre le concept de récursivité.
Savoir ce qu’est un nœud, un sous-arbre gauche et un sous-arbre droit.
Connaître la notion d’arbre vide (NIL).
Consignes : Écris une fonction affiche(T) (où T est l’arbre) qui respecte ces règles :
Si l’arbre est vide, n’affiche rien.
Si c’est un nœud, affiche : ( suivi de son sous-arbre gauche (appel récursif), puis sa valeur, puis son sous-arbre droit (appel récursif), et enfin ).
Exemple d’affichage attendu : Pour un arbre où ‘A’ est la racine, ‘B’ est son fils gauche, ‘C’ est le fils droit de ‘B’, et ‘D’ est le fils droit de ‘A’, on doit obtenir : ((B(C))A(D)).
Solution :
Ceci est un parcours infixe un peu spécial !
VARIABLE
T : arbre
x : noeud
DEBUT
AFFICHE(T) :
si T ≠ NIL :
x ← T.racine
affiche "("
AFFICHE(x.gauche) // Appel récursif pour le sous-arbre gauche
affiche x.clé // Affiche la valeur du noeud actuel
AFFICHE(x.droit) // Appel récursif pour le sous-arbre droit
affiche ")"
fin si
FIN
Testons avec l’exemple ((B(C))A(D)) :
AFFICHE(A) :
Affiche (
Appel AFFICHE(B) :
Affiche (
Appel AFFICHE(NIL) : (rien affiché)
Affiche B
Appel AFFICHE(C) :
Affiche (
Appel AFFICHE(NIL) : (rien affiché)
Affiche C
Appel AFFICHE(NIL) : (rien affiché)
Affiche )
Affiche )
Affiche A
Appel AFFICHE(D) :
Affiche (
Appel AFFICHE(NIL) : (rien affiché)
Affiche D
Appel AFFICHE(NIL) : (rien affiché)
Affiche )
Affiche )
Ce qui donne bien ((B(C))A(D)). Mission accomplie !
Exercice 4 : L’Archéologue de l’Arbre 🕵️♀️
Le défi : À partir de la « recette » parenthésée de l’exercice précédent, retrouver la forme de l’arbre. C’est l’inverse du défi précédent !
Comprendre la structure d’un arbre binaire (nœuds, sous-arbres gauche/droit).
Consignes :
Dessine l’arbre binaire qui produit la sortie (1((2)3)).
De manière générale, explique comment « reconstruire » un arbre à partir de cette notation parenthésée.
Solution :
Dessin de l’arbre (1((2)3)) :
On cherche la valeur centrale du niveau le plus haut : c’est le 1. Le 1 est la racine.
Ce qui est à gauche du 1 (entre la première parenthèse et 1) est le sous-arbre gauche. Ici, c’est ((2)3).
Ce qui est à droite du 1 (entre 1 et la dernière parenthèse) est le sous-arbre droit. Ici, c’est vide (il n’y a rien).
Maintenant, on se concentre sur le sous-arbre gauche ((2)3) :
La valeur centrale est 3. C’est donc la racine du sous-arbre gauche du 1.
Ce qui est à gauche du 3 (entre la parenthèse et 3) est le sous-arbre gauche de 3. C’est (2).
Ce qui est à droite du 3 (entre 3 et la parenthèse) est le sous-arbre droit de 3. C’est vide.
Enfin, on regarde (2) :
La valeur est 2. C’est la racine du sous-arbre gauche de 3.
Ses sous-arbres gauche et droit sont vides.
Donc l’arbre est :
Racine : 1
Fils gauche de 1 : 3
Fils droit de 1 : vide
Fils gauche de 3 : 2
Fils droit de 3 : vide
Fils gauche de 2 : vide
Fils droit de 2 : vide
Comment retrouver l’arbre général ? Cette notation est le résultat d’un parcours infixe récursif. La clé est de trouver la racine du (sous-)arbre actuel.
Chaque ensemble de parenthèses (...) représente un (sous-)arbre.
À l’intérieur de ces parenthèses, l’élément qui n’est PAS entre d’autres parenthèses (ou qui n’est pas un appel récursif) est la racine de ce (sous-)arbre.
Tout ce qui précède cette racine est son sous-arbre gauche.
Tout ce qui suit cette racine est son sous-arbre droit.
On applique ce principe récursivement pour les sous-arbres gauche et droit jusqu’à ce qu’on arrive à des arbres vides (qui ne sont pas affichés). C’est comme déconstruire une expression mathématique, en identifiant l’opérateur principal en premier.
Exercice 5 : Les Arbres Jumelés 👯♀️
Le défi : Apprendre à Python comment comparer deux arbres binaires pour voir s’ils sont identiques. C’est comme enseigner à l’ordinateur à reconnaître des jumeaux !
Prérequis :
Avoir une compréhension de la programmation orientée objet (POO) en Python (classes, objets, méthodes).
Savoir ce qu’est la méthode spéciale __eq__ en Python (pour la comparaison ==).
Comprendre la récursivité.
Savoir ce qu’est un arbre vide (représenté ici par None ou NIL).
Consignes : Ajoute une méthode __eq__ à une classe Noeud (ou ArbreBinaire) qui permet de tester l’égalité entre deux arbres binaires avec l’opérateur ==. Attention, il y a un piège !
Le piège : Deux arbres sont égaux si et seulement si :
Ils sont tous les deux vides.
Ou ils ont la même valeur à leur racine, et leurs sous-arbres gauches sont égaux, ET leurs sous-arbres droits sont égaux. La récursivité est votre amie ici !
Solution (en Python) :
On imagine une classe Noeud simple :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
# Méthode __eq__ à ajouter
def __eq__(self, autre_arbre):
# Cas 1 : Si les deux sont None (arbres vides), ils sont égaux
if self is None and autre_arbre is None:
return True
# Cas 2 : Si l'un est None et l'autre non, ils sont différents
if self is None or autre_arbre is None:
return False
# Cas 3 : Les deux ne sont pas None. On compare les clés et les sous-arbres.
# Attention : la comparaison récursive des sous-arbres !
# 'self.gauche == autre_arbre.gauche' va appeler récursivement __eq__
# 'self.droit == autre_arbre.droit' va appeler récursivement __eq__
return (self.cle == autre_arbre.cle and
self.gauche == autre_arbre.gauche and
self.droit == autre_arbre.droit)
# Une méthode pour la représentation pour rendre l'affichage plus clair
def __repr__(self):
return f"Noeud({self.cle})"
Explication du piège et de la solution : Le piège classique est de ne pas gérer correctement les cas où un ou les deux arbres sont vides (None). La solution élégante utilise la récursivité et gère les cas None au début. Lorsque self.gauche == autre_arbre.gauche est évalué, Python appelle automatiquement la méthode __eq__ sur ces sous-arbres, même s’ils sont None (ce qui est géré par les premières conditions).
Exemples :
Python
# Créons quelques arbres
arbre1 = Noeud(10, Noeud(5), Noeud(15))
arbre2 = Noeud(10, Noeud(5), Noeud(15)) # Identique à arbre1
arbre3 = Noeud(10, Noeud(5), Noeud(20)) # Différent (clé droite)
arbre4 = Noeud(10, Noeud(5)) # Différent (pas de fils droit)
print(arbre1 == arbre2) # True
print(arbre1 == arbre3) # False
print(arbre1 == arbre4) # False
# Arbres vides
arbre_vide1 = None
arbre_vide2 = None
print(arbre_vide1 == arbre_vide2) # True (car les deux sont None)
# Arbre vide vs non vide
print(arbre1 == arbre_vide1) # False
Exercice 6 : L’Arbre Parfait du Constructeur 📐
Le défi : Construire un arbre binaire « parfait » d’une certaine hauteur. Un arbre parfait est un arbre binaire où tous les nœuds (sauf les feuilles) ont exactement deux fils, et toutes les feuilles sont à la même profondeur. C’est le « Carré de l’Arbre » !
Prérequis :
Comprendre la définition d’un arbre binaire parfait.
Maîtriser la récursivité.
Savoir comment créer un nœud d’arbre (comme avec la classe Noeud de l’exercice 5).
Consignes : Écris une fonction parfait(h) qui prend un entier h (hauteur, ge0) et renvoie un arbre binaire parfait de cette hauteur.
Hauteur 0 : un arbre vide (None).
Hauteur 1 : un seul nœud (la racine).
Hauteur 2 : une racine, deux fils (gauche et droit).
Etc.
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
# Pour visualiser l'arbre facilement (peut être amélioré)
return f"({self.gauche.__repr__() if self.gauche else 'NIL'}) {self.cle} ({self.droit.__repr__() if self.droit else 'NIL'})"
def parfait(h):
if h == 0:
return None # Un arbre de hauteur 0 est un arbre vide
else:
# La clé peut être n'importe quoi, on peut utiliser h pour l'exemple
# On construit un noeud, dont les fils sont des arbres parfaits de hauteur h-1
return Noeud(f'Niveau{h}', parfait(h-1), parfait(h-1))
# Exemples :
# print(parfait(0)) # None
# print(parfait(1)) # (NIL) Niveau1 (NIL)
# print(parfait(2)) # ((NIL) Niveau1 (NIL)) Niveau2 ((NIL) Niveau1 (NIL))
# print(parfait(3)) # (((NIL) Niveau1 (NIL)) Niveau2 ((NIL) Niveau1 (NIL))) Niveau3 (((NIL) Niveau1 (NIL)) Niveau2 ((NIL) Niveau1 (NIL)))
Explication : L’idée clé est que pour construire un arbre parfait de hauteur h, on crée une racine, et ses deux fils doivent être des arbres parfaits de hauteur h-1. C’est la définition même de la récursivité appliquée à la structure. Le cas de base est h=0, où l’arbre est vide.
Exercice 7 : Le Peigne Gauche du Coiffeur 💇♂️
Le défi : Construire un arbre binaire « peigne gauche » d’une certaine hauteur. C’est l’opposé de l’arbre complet ! Chaque nœud n’a qu’un fils gauche, et son fils droit est toujours vide.
Prérequis :
Comprendre la définition d’un arbre filiforme (ici, spécifiquement un « peigne gauche »).
Maîtriser la récursivité.
Savoir comment créer un nœud d’arbre (classe Noeud).
Consignes : Écris une fonction peigne_gauche(h) qui prend un entier h (hauteur, ge0) et renvoie un peigne gauche de cette hauteur.
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
return f"({self.gauche.__repr__() if self.gauche else 'NIL'}) {self.cle} ({self.droit.__repr__() if self.droit else 'NIL'})"
def peigne_gauche(h):
if h == 0:
return None # Un peigne de hauteur 0 est un arbre vide
else:
# La racine a un fils gauche qui est un peigne gauche de hauteur h-1
# et un fils droit vide (None)
return Noeud(f'Niveau{h}', peigne_gauche(h-1), None)
# Exemples :
# print(peigne_gauche(0)) # None
# print(peigne_gauche(1)) # (NIL) Niveau1 (NIL)
# print(peigne_gauche(2)) # ((NIL) Niveau1 (NIL)) Niveau2 (NIL)
# print(peigne_gauche(3)) # (((NIL) Niveau1 (NIL)) Niveau2 (NIL)) Niveau3 (NIL)
Explication : Le principe est similaire à parfait(h). Pour un peigne gauche de hauteur h, la racine a un fils gauche qui est un peigne gauche de hauteur h-1, et son fils droit est toujours None. Le cas de base est h=0 pour l’arbre vide.
Exercice 8 : L’Inspecteur de Peignes 🔎
Le défi : Vérifier si un arbre donné est bien un « peigne gauche ». C’est l’inverse du défi précédent, un vrai travail d’inspecteur !
Prérequis :
Comprendre la définition d’un peigne gauche.
Maîtriser la récursivité.
Savoir manipuler les arbres (classe Noeud, vérification de None pour les fils).
Consignes : Écris une fonction est_peigne_gauche(T) qui renvoie True si l’arbre T est un peigne gauche, et False sinon.
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def est_peigne_gauche(T):
if T is None:
return True # Un arbre vide est considéré comme un peigne gauche (hauteur 0)
# Si le fils droit n'est PAS vide, ce n'est pas un peigne gauche
if T.droit is not None:
return False
# Si le fils droit EST vide, on vérifie récursivement le sous-arbre gauche
# Si le fils gauche est aussi None, c'est une feuille qui n'a pas de fils droit,
# donc c'est OK pour un peigne.
return est_peigne_gauche(T.gauche)
# Exemples :
# peigne_ok = peigne_gauche(3)
# print(est_peigne_gauche(peigne_ok)) # True
# arbre_non_peigne = Noeud('A', Noeud('B'), Noeud('C')) # A a un fils droit
# print(est_peigne_gauche(arbre_non_peigne)) # False
# arbre_non_peigne2 = Noeud('A', Noeud('B', droit=Noeud('C'))) # B a un fils droit
# print(est_peigne_gauche(arbre_non_peigne2)) # False
# print(est_peigne_gauche(None)) # True
Explication : La fonction est récursive.
Cas de base : Si l’arbre est vide (T is None), c’est un peigne gauche (le plus petit des peignes).
Condition de non-peigne : Si le nœud actuel a un fils droit (T.droit is not None), ce n’est PAS un peigne gauche, donc on renvoie False immédiatement.
Appel récursif : Si le fils droit est bien vide, on doit juste vérifier que le sous-arbre gauche est lui-même un peigne gauche. On appelle donc est_peigne_gauche sur T.gauche.
Exercice 9 : Le Tour de Passe-Passe Infixe 🧙♂️
Le défi : Construire différents arbres de même taille et avec les mêmes valeurs, mais qui donnent le même résultat lors d’un parcours infixe. C’est un peu de la magie des arbres !
Prérequis :
Comprendre le parcours infixe (PARCOURS-INFIXE de la leçon).
Savoir dessiner un arbre binaire.
Consignes : Donne cinq arbres binaires différents de taille 3, contenant les valeurs 1, 2, et 3, et pour lesquels un parcours infixe affiche toujours :
1
2
3
dans cet ordre.
Solution :
Un parcours infixe affiche : sous-arbre gauche, racine, sous-arbre droit. Pour que l’affichage soit 1, 2, 3, cela signifie que le 1 est soit la racine du sous-arbre gauche le plus à gauche, soit une feuille qui est le premier élément parcouru. Le 2 sera la racine d’un sous-arbre central, et le 3 sera le dernier élément.
Arbre « virgule inversée » (2 en haut, 3 fils droit de 1) :
Racine : 2
Fils gauche : 1
Fils droit de 1 : 3
Parcours infixe : ( (NIL) 1 ( (NIL) 3 (NIL) ) ) 2 (NIL) => 1, 3, 2. Oops ! Ça ne marche pas pour cet ordre. Mon erreur, celui-ci donne 1, 3, 2.Correction pour 5 arbres valides (plus difficile que ça en a l’air !) : Un parcours infixe trie toujours les éléments s’il s’agit d’un Arbre Binaire de Recherche (ABR). Pour un arbre binaire quelconque, ce n’est pas garanti.Si les valeurs sont 1, 2, 3 et que l’ordre infixe est 1, 2, 3, cela signifie que 1 est la plus petite valeur du sous-arbre gauche, 2 est la racine ou une valeur intermédiaire, et 3 est la plus grande valeur du sous-arbre droit.Reprenons les 5 arbres binaires possibles avec 3 nœuds (sans valeur spécifique pour le moment) :
(X (Y (Z))) : Peigne gauche (Racine, fg, fg-fg)
(X (Y) (Z)) : Complet (Racine, fg, fd)
( (X) Y (Z)) : Asymétrique gauche (Racine, fd, fg-fd)
Maintenant, on affecte les valeurs 1, 2, 3 pour que l’ordre infixe soit 1, 2, 3 :
Arbre 1 (Peigne gauche) :
Nœud 3 est la racine.
Nœud 2 est le fils gauche de 3.
Nœud 1 est le fils gauche de 2.
Parcours Infixe : 1, 2, 3
Arbre 2 (Complet) :
Nœud 2 est la racine.
Nœud 1 est le fils gauche de 2.
Nœud 3 est le fils droit de 2.
Parcours Infixe : 1, 2, 3
Arbre 3 (Asymétrique gauche) :
Nœud 3 est la racine.
Nœud 1 est le fils gauche de 3.
Nœud 2 est le fils droit de 1.
Parcours Infixe : 1, 2, 3
Arbre 4 (Asymétrique droite) :
Nœud 1 est la racine.
Nœud 3 est le fils droit de 1.
Nœud 2 est le fils gauche de 3.
Parcours Infixe : 1, 2, 3
Arbre 5 (Peigne droit) :
Nœud 1 est la racine.
Nœud 2 est le fils droit de 1.
Nœud 3 est le fils droit de 2.
Parcours Infixe : 1, 2, 3
Ces cinq arbres différents, même s’ils ont des structures distinctes, produiront le même ordre 1, 2, 3 lors d’un parcours infixe. C’est fascinant, non ?
Exercice 10 : La Salle des Mystères 🧐
Le défi : Comprendre pourquoi une bibliothèque (ici, une base de données de salles) contient un nombre si précis de salles. C’est une énigme de combinaison !
Prérequis :
Comprendre le principe des combinaisons ou des permutations simples.
Connaître les bases de l’alphabet.
Contexte : Une bibliothèque contient 17576 salles. Chaque salle est identifiée par un code unique.
Consignes : Pourquoi la bibliothèque donnée en exemple au début de ce chapitre contient-elle 17576 salles ?
Solution :
Ce nombre nous fait penser à quelque chose qui utilise l’alphabet !
L’alphabet latin contient 26 lettres.
Si chaque salle est identifiée par un code, et que ce code est composé de lettres (par exemple, « AAA », « AAB », « ABA », etc.), on peut facilement obtenir ce nombre.
26times26times26=263=17576
Cela signifie que chaque salle est probablement identifiée par un code de 3 lettres majuscules (ou minuscules, selon la convention) de l’alphabet latin. C’est une combinaison simple avec répétition.
1ère lettre : 26 choix (A-Z)
2ème lettre : 26 choix (A-Z)
3ème lettre : 26 choix (A-Z)
Total = 26times26times26=17576.
C’est une astuce courante pour générer des identifiants uniques dans de nombreux systèmes !
Exercice 11 : Les Architectes d’ABR 🏗️
Le défi : Dessiner tous les Arbres Binaires de Recherche (ABR) possibles avec seulement trois nœuds, et contenant les valeurs 1, 2, et 3.
Prérequis :
Comprendre la définition d’un Arbre Binaire de Recherche (ABR) (les éléments plus petits à gauche, les plus grands à droite).
Savoir dessiner un arbre binaire.
Consignes : Dessine tous les ABR possibles formés de trois nœuds et contenant les entiers 1, 2 et 3.
Solution :
Pour un ABR, la position des éléments dépend de leur valeur. Il n’y a pas autant de formes différentes que pour les arbres binaires « normaux » avec un même nombre de nœuds.
Les 5 formes d’arbres binaires avec 3 nœuds (de l’Exercice 1) peuvent être utilisées, mais avec les contraintes des ABR, seules certaines configurations sont valides pour les valeurs 1, 2, 3.
Voici les 5 ABR uniques avec les valeurs 1, 2, 3 :
Racine = 1 (Peigne droit) :
Racine : 1
Fils droit : 2
Fils droit de 2 : 3
Racine = 2 (Arbre complet) :
Racine : 2
Fils gauche : 1
Fils droit : 3
Racine = 3 (Peigne gauche) :
Racine : 3
Fils gauche : 2
Fils gauche de 2 : 1
Racine = 1 (1 est la racine, 3 est son fils droit, 2 est le fils gauche de 3) :
Racine : 1
Fils droit : 3
Fils gauche de 3 : 2
Racine = 3 (3 est la racine, 1 est son fils gauche, 2 est le fils droit de 1) :
Racine : 3
Fils gauche : 1
Fils droit de 1 : 2
Ce sont les 5 formes possibles. Remarquez que l’ordre des valeurs dans un ABR est la clé de sa structure.
Exercice 12 : Le Chasseur de Minimum 🎯
Le défi : Trouver le plus petit élément dans un Arbre Binaire de Recherche (ABR). C’est comme chercher la petite graine au fond du jardin !
Prérequis :
Comprendre la définition d’un ABR (les éléments plus petits sont à gauche).
Maîtriser la récursivité ou les boucles (itératif).
Savoir gérer les arbres vides (None).
Consignes :
Dans un ABR, où se trouve le plus petit élément ?
Écris une fonction minimum(a) qui renvoie le plus petit élément de l’ABR a.
Si l’arbre a est vide, la fonction renvoie None.
Solution (en Python) :
Où se trouve le plus petit élément ? Dans un ABR, le plus petit élément se trouve toujours tout à gauche ! On part de la racine et on descend toujours par le sous-arbre gauche jusqu’à ce qu’on ne puisse plus aller à gauche (c’est-à-dire jusqu’à atteindre une feuille ou un nœud dont le fils gauche est None).
Fonction minimum(a) (version récursive) :Pythonclass Noeud: def __init__(self, cle, gauche=None, droit=None): self.cle = cle self.gauche = gauche self.droit = droit def minimum(a): if a is None: return None # Si l'arbre est vide, pas de minimum if a.gauche is None: return a.cle # Si pas de fils gauche, le noeud actuel est le plus petit else: return minimum(a.gauche) # Sinon, on cherche dans le sous-arbre gauche
Fonction minimum(a) (version itérative – avec boucle tant que) :Pythondef minimum_iteratif(a): if a is None: return None courant = a while courant.gauche is not None: courant = courant.gauche return courant.cle
Les deux versions fonctionnent parfaitement. La version itérative est parfois préférée pour éviter la profondeur de récursion sur des arbres très déséquilibrés.
Exercice 13 : L’Ajouteur Intelligent d’ABR 🧠
Le défi : Modifier l’algorithme d’insertion dans un ABR pour qu’il n’ajoute pas un élément s’il est déjà présent. C’est comme un filtre anti-doublons !
Prérequis :
Comprendre l’algorithme d’insertion dans un ABR (vu en cours).
Savoir gérer les cas où la clé est déjà trouvée.
Connaître la structure de la classe Noeud.
Consignes : Écris une variante du programme d’insertion d’une clé dans un ABR qui n’ajoute pas l’élément x à l’arbre a s’il est déjà dedans.
Solution (en Python) :
On se base sur l’algorithme d’insertion vu en cours :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
return f"Noeud({self.cle})"
def ajoute_sans_doublon(arbre, nouvelle_cle):
# Cas 1 : L'arbre est vide, la nouvelle_cle devient la racine
if arbre is None:
return Noeud(nouvelle_cle)
courant = arbre # Pointeur pour parcourir l'arbre
parent = None # Pointeur pour retenir le parent du noeud où insérer
while courant is not None:
if nouvelle_cle == courant.cle:
# La clé existe déjà, on ne fait rien et on renvoie l'arbre inchangé
return arbre
parent = courant
if nouvelle_cle < courant.cle:
courant = courant.gauche
else: # nouvelle_cle > courant.cle
courant = courant.droit
# On a trouvé l'emplacement d'insertion (courant est None, parent est le bon noeud)
if nouvelle_cle < parent.cle:
parent.gauche = Noeud(nouvelle_cle)
else:
parent.droit = Noeud(nouvelle_cle)
return arbre # On renvoie la racine de l'arbre (qui n'a pas changé)
# Exemple d'utilisation :
# arbre_test = Noeud(10, Noeud(5), Noeud(15))
# print(arbre_test)
# ajoute_sans_doublon(arbre_test, 7) # Ajoute 7
# print(arbre_test)
# ajoute_sans_doublon(arbre_test, 5) # N'ajoute pas 5 (déjà présent)
# print(arbre_test)
Explication : L’algorithme de parcours est le même que pour la recherche. La différence est que si à un moment donné nouvelle_cle == courant.cle, on sait que l’élément est déjà là, et on s’arrête sans rien ajouter. Si on arrive à courant is None sans avoir trouvé la clé, alors on insère le nouveau nœud comme d’habitude.
Exercice 14 : Le Compteur Flexible d’ABR ⚖️
Le défi : Compter les occurrences d’une valeur dans un ABR, même si l’ABR n’a pas été construit « proprement » (c’est-à-dire que des doublons peuvent être à gauche ou à droite de la racine). On veut être malin et ne pas chercher là où on est sûr de ne rien trouver !
Prérequis :
Comprendre la définition d’un ABR.
Maîtriser la récursivité.
Savoir parcourir un arbre et prendre des décisions basées sur les valeurs.
Contexte : Dans un ABR « normal », si une clé est égale à la racine, elle ne devrait pas apparaître dans les sous-arbres gauche ou droit (selon la convention stricte y.clé < x.clé et x.clé < y.clé). Mais ici, on suppose que les doublons peuvent être présents à gauche OU à droite (y.clé <= x.clé et x.clé <= y.clé). L’objectif est de ne pas chercher inutilement.
Consignes : Écris une fonction compte(x, a) qui renvoie le nombre d’occurrences de x dans l’ABR a. On ne suppose pas que l’arbre a été construit à partir de la fonction ajoute (où les doublons seraient gérés de manière unique), mais qu’il s’agit d’un ABR (donc l’ordre est respecté). Cependant, une valeur égale à la racine peut se trouver encore dans le sous-arbre gauche OU dans le sous-arbre droit. On s’attachera à ne pas descendre dans les sous-arbres dans lesquels on est certain que la valeur x ne peut apparaître.
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
return f"Noeud({self.cle})"
def compte(x, a):
if a is None:
return 0 # Si l'arbre est vide, 0 occurrences
nb_occurrences = 0
if x == a.cle:
nb_occurrences = 1 # On a trouvé une occurrence à la racine
# Cas 1 : La clé recherchée est plus petite que la clé du noeud actuel
# On peut chercher dans le sous-arbre gauche. On ne cherche PAS à droite.
if x < a.cle:
nb_occurrences += compte(x, a.gauche)
# Cas 2 : La clé recherchée est plus grande que la clé du noeud actuel
# On peut chercher dans le sous-arbre droit. On ne cherche PAS à gauche.
elif x > a.cle:
nb_occurrences += compte(x, a.droit)
# Cas 3 : La clé recherchée est ÉGALE à la clé du noeud actuel
# C'est le cas "flexible" : la clé peut être présente dans les deux sous-arbres.
# On doit donc chercher dans les DEUX sous-arbres pour les doublons.
else: # x == a.cle
nb_occurrences += compte(x, a.gauche)
nb_occurrences += compte(x, a.droit)
return nb_occurrences
# Exemple d'utilisation :
# Construisons un ABR "non strict"
# 10
# / \
# 5 15
# / \ / \
# 5 7 15 20
arbre_flexible = Noeud(10,
Noeud(5, Noeud(5), Noeud(7)),
Noeud(15, Noeud(15), Noeud(20)))
print(f"Occurrences de 5 : {compte(5, arbre_flexible)}") # Devrait être 2
print(f"Occurrences de 10 : {compte(10, arbre_flexible)}") # Devrait être 1
print(f"Occurrences de 15 : {compte(15, arbre_flexible)}") # Devrait être 2
print(f"Occurrences de 20 : {compte(20, arbre_flexible)}") # Devrait être 1
print(f"Occurrences de 8 : {compte(8, arbre_flexible)}") # Devrait être 0
Explication : La logique de recherche est similaire à celle d’un ABR « normal », mais avec une condition supplémentaire pour les doublons :
Si x < a.cle, on va seulement à gauche.
Si x > a.cle, on va seulement à droite.
MAIS, si x == a.cle, on incrémente le compteur, puis on continue à chercher dans les deux sous-arbres (a.gauche et a.droit). C’est là la subtilité ! Cela permet de trouver toutes les occurrences de x, même si elles sont réparties de manière non standard (mais toujours « ABR-compatible ») dans l’arbre.
Exercice 15 : L’Ordonnateur d’Arbres 📋
Le défi : Extraire tous les éléments d’un ABR et les ranger dans un tableau trié. C’est comme vider une boîte triée dans un tiroir !
Prérequis :
Comprendre le parcours infixe d’un arbre binaire.
Comprendre les propriétés d’un ABR (le parcours infixe les retourne dans l’ordre croissant).
Savoir manipuler des tableaux (listes en Python).
Avoir une classe ABR ou Noeud (avec une racine).
Consignes :
Écris une fonction remplir(a, t) qui ajoute tous les éléments de l’arbre a dans le tableau t (en utilisant t.append(x)) dans l’ordre infixe.
Ajoute ensuite une méthode lister(self) à la classe ABR (ou Noeud pour simplifier) qui renvoie un nouveau tableau contenant tous les éléments de l’ABR self par ordre croissant.
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
return f"Noeud({self.cle})"
# Méthode lister à ajouter à la classe Noeud pour l'exercice
def lister(self):
resultat = []
_remplir_infixe_recursif(self, resultat) # Appel à la fonction helper
return resultat
# Partie 1 : Fonction remplir
def remplir(a, t):
if a is not None:
remplir(a.gauche, t) # Parcourt le sous-arbre gauche
t.append(a.cle) # Ajoute la clé du noeud actuel
remplir(a.droit, t) # Parcourt le sous-arbre droit
# On peut aussi encapsuler remplir comme une fonction "privée" ou helper
# pour la méthode lister
def _remplir_infixe_recursif(noeud_courant, liste_resultat):
if noeud_courant is not None:
_remplir_infixe_recursif(noeud_courant.gauche, liste_resultat)
liste_resultat.append(noeud_courant.cle)
_remplir_infixe_recursif(noeud_courant.droit, liste_resultat)
# Exemple d'utilisation :
# 10
# / \
# 5 15
# / \ /
# 3 7 12
arbre_exemple = Noeud(10,
Noeud(5, Noeud(3), Noeud(7)),
Noeud(15, Noeud(12)))
tableau_vide = []
remplir(arbre_exemple, tableau_vide)
print(f"Tableau rempli avec remplir : {tableau_vide}") # Devrait afficher [3, 5, 7, 10, 12, 15]
# Utilisation de la méthode lister (si vous avez intégré la méthode à la classe Noeud)
print(f"Tableau rempli avec lister : {arbre_exemple.lister()}") # Devrait afficher [3, 5, 7, 10, 12, 15]
Explication :
La fonction remplir (ou _remplir_infixe_recursif) est une implémentation directe du parcours infixe. L’ordre infixe sur un ABR garantit que les éléments sont visités dans l’ordre croissant.
La méthode lister de la classe Noeud (ou ABR si vous en avez une) initialise un tableau vide, appelle la fonction remplir (ou sa version _remplir_infixe_recursif) pour le remplir, puis renvoie ce tableau. C’est une manière élégante d’intégrer cette fonctionnalité à l’objet arbre.
Exercice 16 : Le Triage d’Arbres Magique ✨
Le défi : Utiliser un ABR pour trier un tableau d’entiers. C’est comme une baguette magique qui range vos nombres !
Prérequis :
Avoir la fonction d’insertion dans un ABR (Exercice 13 ou sa version simple).
Avoir la méthode lister (Exercice 15).
Comprendre le concept de complexité algorithmique (O(n), O(log_2(n)), etc.).
Consignes :
En utilisant les fonctions des exercices précédents (insertion dans un ABR et lister), écris une fonction trier(t) qui reçoit en argument un tableau d’entiers et renvoie un tableau trié contenant les mêmes éléments.
Quelle est l’efficacité de ce tri ?
Solution (en Python) :
Python
# On réutilise les classes et fonctions précédentes ou on les suppose définies
# (Noeud, ajoute_sans_doublon, _remplir_infixe_recursif)
# Assurez-vous que ajoute_sans_doublon est disponible ou utilisez une version simple d'ajout
def ajoute_simple(arbre, nouvelle_cle):
if arbre is None:
return Noeud(nouvelle_cle)
courant = arbre
parent = None
while courant is not None:
parent = courant
if nouvelle_cle < courant.cle:
courant = courant.gauche
else:
courant = courant.droit
if nouvelle_cle < parent.cle:
parent.gauche = Noeud(nouvelle_cle)
else:
parent.droit = Noeud(nouvelle_cle)
return arbre
def trier(tableau_entiers):
# Étape 1 : Créer un ABR et y insérer tous les éléments du tableau
arbre_de_tri = None
for element in tableau_entiers:
# On utilise ajoute_simple pour éviter les doublons si nécessaire,
# ou ajoute_sans_doublon pour l'exercice 13
if arbre_de_tri is None: # Cas particulier pour la première insertion
arbre_de_tri = Noeud(element)
else:
ajoute_simple(arbre_de_tri, element) # ou ajoute_sans_doublon
# Étape 2 : Lister les éléments de l'ABR en ordre infixe pour obtenir le tableau trié
# On utilise la fonction _remplir_infixe_recursif (ou la méthode lister)
tableau_trie = []
_remplir_infixe_recursif(arbre_de_tri, tableau_trie)
return tableau_trie
# Exemple d'utilisation :
tableau_initial = [5, 3, 8, 1, 9, 2, 7, 4, 6]
tableau_trie = trier(tableau_initial)
print(f"Tableau initial : {tableau_initial}")
print(f"Tableau trié (méthode ABR) : {tableau_trie}") # Devrait afficher [1, 2, 3, 4, 5, 6, 7, 8, 9]
Efficacité de ce tri :
Ce tri est appelé le tri par arbre binaire. Son efficacité dépend de la forme de l’ABR construit :
Construction de l’arbre : Pour insérer n éléments, chaque insertion prend en moyenne O(log_2(n)) (si l’arbre reste équilibré) ou O(n) dans le pire des cas (si l’arbre devient filiforme). Donc, la phase de construction prend en moyenne O(nlog_2(n)) et dans le pire des cas O(n2).
Parcours infixe : Pour parcourir tous les n éléments de l’arbre, c’est O(n).
Complexité totale :
En moyenne : O(nlog_2(n)). C’est très efficace, comparable à des tris comme le Quicksort ou le Mergesort.
Dans le pire des cas (quand l’arbre devient filiforme, par exemple si les nombres sont déjà triés ou presque triés) : O(n2). C’est beaucoup moins efficace, comparable à des tris comme le tri à bulles.
Pour garantir une bonne performance dans tous les cas, il faudrait utiliser des ABR auto-équilibrés (comme les arbres AVL ou Rouge-Noir), mais c’est une autre histoire pour plus tard ! 😉
Exercice 17 : L’Affichage Indenté de l’Explorateur 🗂️
Le défi : Afficher un arbre d’une manière qui ressemble à l’explorateur de fichiers de votre ordinateur, avec une indentation qui montre la profondeur de chaque nœud.
Prérequis :
Comprendre le parcours préfixe (racine, gauche, droite).
Maîtriser la récursivité.
Savoir manipuler des chaînes de caractères (ajouter des espaces pour l’indentation).
Consignes : Écris une fonction affiche(a) qui affiche une arborescence selon un parcours préfixe, avec un nœud par ligne et une marge proportionnelle à la profondeur du nœud.
Indication : Écris une fonction récursive qui prend un paramètre supplémentaire : une chaîne de caractères (composée d’espaces) à afficher avant la valeur du nœud.
Exemple de sortie attendue :
A
B
C
D
E
F
G
H
(Les « tabulations » sont en fait des espaces, 2 ou 4 par niveau par exemple.)
Solution (en Python) :
Python
class Noeud:
def __init__(self, cle, gauche=None, droit=None):
self.cle = cle
self.gauche = gauche
self.droit = droit
def __repr__(self):
return str(self.cle)
def affiche_arborescence(arbre, indentation=""):
if arbre is not None:
print(f"{indentation}{arbre.cle}") # Affiche le noeud actuel avec l'indentation
# Appel récursif pour le sous-arbre gauche, augmente l'indentation
affiche_arborescence(arbre.gauche, indentation + " ") # Ajoutez 2 espaces par niveau
# Appel récursif pour le sous-arbre droit, augmente l'indentation
affiche_arborescence(arbre.droit, indentation + " ")
# Exemple d'utilisation avec l'arbre du cours :
# A
# / \
# B F
# / \ / \
# C D G H
# / /
# E I
# \
# J
arbre_test = Noeud('A',
Noeud('B',
Noeud('C', Noeud('E')),
Noeud('D')),
Noeud('F',
Noeud('G', Noeud('I', droit=Noeud('J'))),
Noeud('H')))
print("Affichage de l'arborescence :")
affiche_arborescence(arbre_test)
Explication : La fonction affiche_arborescence est récursive et suit l’ordre du parcours préfixe :
Elle gère le cas de base (arbre vide) en ne faisant rien.
Pour un nœud non vide, elle affiche sa cle en la faisant précéder de la indentation actuelle.
Puis elle s’appelle récursivement pour le sous-arbre gauche, en augmentant l’indentation (indentation + " ").
Enfin, elle s’appelle récursivement pour le sous-arbre droit, avec la même indentation augmentée.
Chaque niveau de profondeur ajoute des espaces, créant ainsi l’effet d’arborescence visuelle. C’est super pratique pour débugger ou visualiser la structure d’un arbre !
Exercice 18 : L’Explorateur de Fichiers Python 📂
Le défi : Écrire un programme Python qui explore les répertoires de votre ordinateur et les représente sous forme d’arbre binaire (enfin, une arborescence générale). C’est comme créer votre propre gestionnaire de fichiers !
Prérequis :
Comprendre le concept d’arborescence pour les systèmes de fichiers.
Maîtriser la récursivité.
Savoir utiliser les fonctions du module os de Python (os.listdir, os.path.join, os.path.isdir).
Avoir la fonction d’affichage indenté de l’exercice précédent (affiche_arborescence).
Contexte : Les répertoires de votre ordinateur sont déjà une structure d’arbre. On va la modéliser avec notre structure d’arbre personnalisée.
Consignes :
Écris une fonction Python repertoires(nom_repertoire) qui prend un nom de répertoire et renvoie une arborescence (au sens de notre classe Noeud ou une classe Repertoire dédiée) décrivant la structure récursive de ses sous-répertoires.
Utilise les fonctions os.listdir(), os.path.join(), et os.path.isdir().
Teste le résultat en l’affichant avec la fonction affiche_arborescence de l’exercice précédent.
Solution (en Python) :
Pour cet exercice, on va adapter notre classe Noeud pour qu’elle puisse aussi représenter des répertoires. On pourrait aussi créer une classe Repertoire spécifique.
Python
import os
class NoeudRepertoire:
def __init__(self, nom, enfants=None):
self.nom = nom
# Pour un répertoire, 'enfants' est une liste de NoeudRepertoire
# (et non pas gauche/droit car un répertoire peut avoir plus de 2 sous-répertoires)
self.enfants = enfants if enfants is not None else []
def __repr__(self):
return self.nom
def repertoires(chemin_initial):
# On va construire un noeud pour le répertoire actuel
racine_rep = NoeudRepertoire(os.path.basename(chemin_initial))
try:
# Liste tous les éléments (fichiers et dossiers) dans le répertoire
elements = os.listdir(chemin_initial)
except PermissionError:
# Gérer les erreurs de permission pour ne pas planter le programme
print(f"Permission refusée pour accéder à : {chemin_initial}")
return racine_rep # Retourne juste le noeud sans ses enfants
# On parcourt chaque élément trouvé
for element in elements:
chemin_complet_element = os.path.join(chemin_initial, element)
# Si l'élément est un répertoire, on l'ajoute récursivement
if os.path.isdir(chemin_complet_element):
sous_repertoire_modele = repertoires(chemin_complet_element)
racine_rep.enfants.append(sous_repertoire_modele)
return racine_rep
# Fonction d'affichage adaptée pour la nouvelle structure NoeudRepertoire
def affiche_arborescence_repertoire(arbre_rep, indentation=""):
if arbre_rep is not None:
print(f"{indentation}{arbre_rep.nom}")
for enfant in arbre_rep.enfants:
affiche_arborescence_repertoire(enfant, indentation + " ")
# --- Test du programme ---
# Choisissez un répertoire de test. Attention : plus il est grand, plus ça prendra de temps !
# Un petit répertoire de test est recommandé, par exemple un dossier que vous avez créé
# avec quelques sous-dossiers et fichiers.
repertoire_a_explorer = "./mon_dossier_test" # Remplacez par un chemin réel et pertinent !
# Créez un dossier de test simple si vous n'en avez pas
if not os.path.exists(repertoire_a_explorer):
os.makedirs(os.path.join(repertoire_a_explorer, "sous_dossier1"))
os.makedirs(os.path.join(repertoire_a_explorer, "sous_dossier2", "sous_sous_dossier"))
with open(os.path.join(repertoire_a_explorer, "fichier1.txt"), "w") as f:
f.write("test")
with open(os.path.join(repertoire_a_explorer, "sous_dossier1", "fichier2.py"), "w") as f:
f.write("print('hello')")
print(f"Dossier de test '{repertoire_a_explorer}' créé.")
print(f"\nExploration de l'arborescence à partir de : {repertoire_a_explorer}")
arbre_systeme = repertoires(repertoire_a_explorer)
affiche_arborescence_repertoire(arbre_systeme)
# Nettoyage du dossier de test (optionnel)
# import shutil
# shutil.rmtree(repertoire_a_explorer)
# print(f"\nDossier de test '{repertoire_a_explorer}' supprimé.")
Explication :
Classe NoeudRepertoire : On adapte la classe de nœud. Au lieu de gauche et droit, un répertoire peut avoir enfants (une liste), car un dossier peut contenir plus de deux sous-dossiers.
Fonction repertoires :
Elle crée un NoeudRepertoire pour le chemin actuel.
Elle utilise os.listdir() pour obtenir la liste de tout ce qui se trouve dans ce répertoire.
Pour chaque élément, os.path.join() construit le chemin complet.
os.path.isdir() vérifie si l’élément est un répertoire.
Si c’est un répertoire, la fonction s’appelle elle-même récursivement (repertoires(chemin_complet_element)) pour construire le sous-arbre de ce sous-répertoire, et l’ajoute à la liste enfants du nœud actuel.
Si c’est un fichier, on l’ignore (car l’exercice ne demande que les répertoires).
Un bloc try-except PermissionError est ajouté pour gérer les accès refusés, courants dans les systèmes de fichiers.
Fonction affiche_arborescence_repertoire : Elle est similaire à l’exercice précédent, mais elle itère sur la liste enfants plutôt que d’appeler gauche et droit.
C’est un exemple très concret de l’application des arbres pour modéliser des structures du monde réel !
Exercice 19 : Le Détective XML 🧐
Le défi : Vérifier si des petits extraits XML sont « bien formés », c’est-à-dire s’ils respectent les règles de base de la syntaxe XML.
Prérequis :
Comprendre les bases du format XML (balises ouvrantes, balises fermantes, attributs).
Savoir ce qu’est un document bien formé.
Consignes : Pour chacun des petits documents XML ci-dessous, dis s’il est bien formé. Si ce n’est pas le cas, indique l’erreur.
<a></a>
<a><b></b><b></b></a>
<a><b></B></a>
<a><b></a>
<a></a><a></a>
<a><b id="45" v=’45’></b></a>
<a><b id="45" id="48"></b></a>
<a><b id="45"></b><b id="45"></b></a>
Solution :
Un document XML est bien formé s’il respecte des règles syntaxiques de base :
Il doit y avoir un unique élément racine.
Chaque balise ouverte doit être fermée.
Les balises doivent être correctement imbriquées (pas de chevauchement).
Les noms de balises sont sensibles à la casse (<b> n’est pas la même chose que </B>).
Les attributs doivent avoir des valeurs entre guillemets (" " ou ' ').
Les noms d’attributs doivent être uniques au sein d’une même balise.
Allons-y !
<a></a>
Bien formé. Racine unique, balise ouverte et fermée correctement.
<a><b></b><b></b></a>
Bien formé. Racine unique (<a>), balises imbriquées correctement.
<a><b></B></a>
NON bien formé. Erreur : Sensibilité à la casse. La balise ouvrante est <b> mais la balise fermante est </B>. Les majuscules/minuscules doivent correspondre.
<a><b></a>
NON bien formé. Erreur : Imbrication incorrecte. La balise <b> est ouverte mais n’est pas fermée avant la fermeture de <a>. L’ordre de fermeture doit être l’inverse de l’ordre d’ouverture.
<a></a><a></a>
NON bien formé. Erreur : Multiples racines. Un document XML doit avoir un et un seul élément racine. Ici, il y a deux éléments <a> au niveau le plus haut.
<a><b id="45" v=’45’></b></a>
NON bien formé. Erreur : Les attributs doivent avoir leurs valeurs entre guillemets doubles " " ou guillemets simples ' '. Ici, v=’45’ utilise une apostrophe ouvrante (’) et une apostrophe fermante (’) qui ne sont pas les bons caractères ASCII pour les guillemets simples (qui sont ''). En général, les guillemets doubles sont préférés.
<a><b id="45" id="48"></b></a>
NON bien formé. Erreur : Attributs dupliqués. Un même élément (<b>) ne peut pas avoir deux attributs avec le même nom (id).
<a><b id="45"></b><b id="45"></b></a>
Bien formé. C’est un piège ! Même si les deux éléments <b> ont le même id, l’erreur 7 concernait des attributs dupliqués sur la même balise. Ici, ce sont deux balises <b> différentes, chacune avec son propre attribut id="45". C’est valide en XML bien formé (bien que cela puisse poser problème pour la validation avec un schéma DTD/XSD qui demande des IDs uniques, mais ce n’est pas la question ici).
Exercice 20 : Le Compteur de Nœuds XML 📊
Le défi : Compter le nombre de nœuds (éléments) ayant un certain nom de balise dans un document XML.
Prérequis :
Comprendre la structure d’un document XML comme un arbre.
Maîtriser la récursivité.
Savoir parcourir un arbre (même si la représentation DOM est interne à Python).
Contexte : Lorsque Python analyse un document XML, il le transforme en une structure d’objet appelée « DOM » (Document Object Model), qui est en fait une représentation en arbre ! Un nœud DOM peut avoir des « enfants » (d’autres nœuds DOM).
Consignes : Écris une fonction compte_balise(d, nom_balise) qui prend en argument un nœud DOM d et un nom de balise n (ici, nom_balise), et qui renvoie le nombre de nœuds (éléments) ayant ce nom dans le document.
Solution (en Python) :
On va simuler une structure DOM simple avec des dictionnaires pour les nœuds, car la manipulation réelle du DOM avec xml.etree.ElementTree serait un peu lourde pour l’exercice. L’important est la logique récursive.
Python
# Simulation d'un noeud DOM simple
# Chaque noeud a un 'tag' (nom de balise) et une liste 'children' (ses enfants)
def creer_noeud_dom(tag, children=None):
return {"tag": tag, "children": children if children is not None else []}
def compte_balise(noeud_dom, nom_balise_recherche):
compteur = 0
# 1. Vérifier le noeud actuel
if noeud_dom["tag"] == nom_balise_recherche:
compteur += 1
# 2. Parcourir récursivement les enfants
for enfant in noeud_dom["children"]:
compteur += compte_balise(enfant, nom_balise_recherche) # Appel récursif
return compteur
# Exemple d'utilisation avec une structure XML simulée
# <racine>
# <enfant1>
# <sous_enfant>
# <enfant1/>
# </sous_enfant>
# </enfant1>
# <enfant2/>
# <enfant1/>
# </racine>
arbre_xml_simule = creer_noeud_dom("racine", [
creer_noeud_dom("enfant1", [
creer_noeud_dom("sous_enfant", [
creer_noeud_dom("enfant1")
])
]),
creer_noeud_dom("enfant2"),
creer_noeud_dom("enfant1")
])
print(f"Nombre d'éléments 'enfant1' : {compte_balise(arbre_xml_simule, 'enfant1')}") # Devrait être 2
print(f"Nombre d'éléments 'racine' : {compte_balise(arbre_xml_simule, 'racine')}") # Devrait être 1
print(f"Nombre d'éléments 'bidon' : {compte_balise(arbre_xml_simule, 'bidon')}") # Devrait être 0
Explication : La fonction compte_balise est une fonction récursive qui fait un parcours en profondeur de l’arbre XML :
Cas de base implicite : Si un nœud n’a pas d’enfants, la boucle for ne s’exécute pas, et la fonction renvoie le compteur pour ce seul nœud.
Traitement du nœud actuel : Elle vérifie si le tag (nom de balise) du nœud noeud_dom correspond au nom_balise_recherche. Si oui, elle incrémente le compteur.
Appel récursif pour les enfants : Pour chaque enfant du nœud actuel, elle appelle récursivement compte_balise et ajoute le résultat au compteur.
Cette méthode permet de visiter tous les nœuds de l’arbre et de compter ceux qui correspondent au nom de balise recherché.
Exercice 21 : La Fabrique XML 🏭
Le défi : Générer un document XML avec une structure spécifique et le sauvegarder dans un fichier. C’est comme imprimer un arbre en XML !
Prérequis :
Comprendre le format XML.
Savoir manipuler des fichiers en Python (ouvrir, écrire, fermer).
Utiliser la bibliothèque xml.etree.ElementTree de Python (pour la création d’éléments XML).
Consignes : Écris une fonction gen_doc(n) qui prend un entier n et génère un document XML de la forme : <a><b>0</b><b>1</b>...<b>n - 1</b></a> Et sauve ce document dans un fichier docn.xml.
Solution (en Python) :
Python
import xml.etree.ElementTree as ET
def gen_doc(n):
# Créer l'élément racine 'a'
root_a = ET.Element("a")
# Ajouter les éléments 'b' de 0 à n-1
for i in range(n):
element_b = ET.SubElement(root_a, "b") # Crée un sous-élément 'b' sous 'a'
element_b.text = str(i) # Définit le contenu textuel de 'b'
# Créer un objet ElementTree à partir de la racine
tree = ET.ElementTree(root_a)
# Construire le nom du fichier
nom_fichier = f"doc{n}.xml"
# Sauvegarder le document XML dans le fichier
try:
# pretty_print=True pour un affichage plus lisible dans le fichier
# encoding="utf-8" pour éviter les problèmes d'encodage
tree.write(nom_fichier, encoding="utf-8", xml_declaration=True, pretty_print=True)
print(f"Document XML sauvegardé dans {nom_fichier}")
except Exception as e:
print(f"Erreur lors de la sauvegarde du fichier : {e}")
# Exemples d'utilisation :
gen_doc(5) # Va créer doc5.xml
gen_doc(10) # Va créer doc10.xml
import xml.etree.ElementTree as ET : Importe la bibliothèque Python standard pour manipuler le XML. C’est pratique et intégré.
ET.Element("a") : Crée l’élément XML de plus haut niveau, la racine <a>.
for i in range(n) : Une boucle pour créer les n éléments <b>.
ET.SubElement(root_a, "b") : Crée un nouvel élément <b> qui est un enfant de root_a.
element_b.text = str(i) : Donne le texte (la valeur numérique i convertie en chaîne) à l’élément <b>.
ET.ElementTree(root_a) : Crée un objet « arbre » XML à partir de l’élément racine.
tree.write(nom_fichier, ...) : Sauvegarde l’arbre XML dans le fichier spécifié. L’option pretty_print=True est très utile pour un affichage lisible.
Exercice 22 : Le Traducteur JSON 🗣️
Le défi : Lire un fichier JSON, interpréter son contenu pour déterminer un mode (« bonjour » ou « bonsoir ») et un nom, puis afficher un message personnalisé. C’est comme créer une petite application de salutations !
Prérequis :
Comprendre les bases du format JSON (objets, paires clé-valeur, chaînes de caractères).
Savoir manipuler des fichiers en Python (ouvrir, lire, fermer).
Utiliser la bibliothèque json de Python (pour lire les fichiers JSON).
Consignes : Écris un programme hello_json.py qui :
Charge un fichier JSON config.json.
Ce fichier config.json contient un dictionnaire avec deux entrées :
"mode" : chaîne de caractères "bonjour" ou "bonsoir"
"nom" : un nom de personne (par exemple, "Toto")
Le programme affiche ensuite « bonjour Toto » ou « bonsoir Toto » en fonction du mode.
Solution (en Python) :
D’abord, créons le fichier config.json pour le test :
JSON
# config.json (copiez/collez ce contenu dans un fichier nommé config.json)
{
"mode": "bonjour",
"nom": "Alice"
}
Vous pouvez modifier « mode » à « bonsoir » ou « nom » à « Bob » pour tester.
Maintenant, le programme hello_json.py :
Python
import json
import os
def hello_json():
nom_fichier_config = "config.json"
# Vérifier si le fichier config.json existe
if not os.path.exists(nom_fichier_config):
print(f"Erreur : Le fichier '{nom_fichier_config}' n'a pas été trouvé.")
print("Veuillez créer un fichier config.json avec le contenu suivant :")
print("""
{
"mode": "bonjour",
"nom": "Toto"
}
""")
return
try:
# Ouvrir et lire le fichier JSON
with open(nom_fichier_config, 'r', encoding='utf-8') as f:
data = json.load(f) # Convertit le contenu JSON en un dictionnaire Python
# Extraire les informations du dictionnaire
mode = data.get("mode") # Utilise .get() pour éviter une erreur si la clé n'existe pas
nom = data.get("nom")
# Vérifier si les clés nécessaires sont présentes
if mode is None or nom is None:
print("Erreur : Le fichier config.json doit contenir les clés 'mode' et 'nom'.")
return
# Afficher le message personnalisé
if mode == "bonjour":
print(f"Bonjour {nom} !")
elif mode == "bonsoir":
print(f"Bonsoir {nom} !")
else:
print(f"Mode inconnu dans config.json : '{mode}'. Je ne sais pas comment saluer {nom}.")
except json.JSONDecodeError as e:
print(f"Erreur de format JSON dans '{nom_fichier_config}' : {e}")
except Exception as e:
print(f"Une erreur inattendue est survenue : {e}")
# Appeler la fonction principale du programme
hello_json()
Explication :
import json : Importe le module json qui gère la conversion entre les chaînes JSON et les objets Python (dictionnaires, listes).
with open(nom_fichier_config, 'r', encoding='utf-8') as f: : Ouvre le fichier config.json en mode lecture ('r'). Le with garantit que le fichier est bien fermé après. encoding='utf-8' est essentiel pour les caractères spéciaux.
data = json.load(f) : C’est la ligne magique ! Elle lit le contenu du fichier et le transforme en un dictionnaire Python.
mode = data.get("mode") et nom = data.get("nom") : Accède aux valeurs associées aux clés "mode" et "nom" dans le dictionnaire Python. Utiliser .get() est plus sûr que data["mode"] car cela renvoie None si la clé n’existe pas, évitant une erreur.
Les conditions if/elif/else : Affichent le message de salutation en fonction de la valeur de mode.
try-except : C’est important pour gérer les erreurs, par exemple si le fichier JSON est mal formé (json.JSONDecodeError) ou s’il n’existe pas.
Ce programme montre bien la simplicité du JSON pour échanger des données structurées et la facilité avec laquelle Python peut les manipuler !