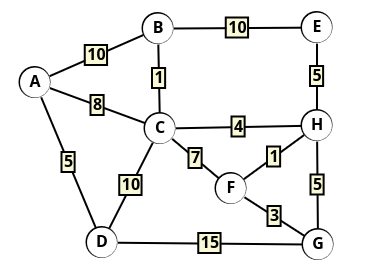
La recherche d’un motif (une sous-chaîne) dans un texte est un problème fondamental en informatique. Que ce soit pour la fonction « Rechercher » de votre éditeur de texte ou pour l’analyse de séquences génomiques en bioinformatique, l’efficacité de ces algorithmes est cruciale.
1. Le problème de la recherche textuelle
L’objectif est de déterminer si une chaîne de caractères appelée motif est présente dans une chaîne plus longue appelée texte, et si oui, à quel(s) indice(s).
Exemple :
- Texte :
L'informatique est la science du traitement automatique.- Motif :
mati- Résultat : Le motif est présent à l’indice 8. (Rappel : l’indice commence à 0 et les espaces comptent).
2. L’algorithme de recherche « Naïf »
L’approche la plus simple consiste à faire glisser le motif devant le texte, caractère par caractère, et à vérifier la correspondance à chaque position.
Fonctionnement :
- On aligne le début du motif avec le début du texte.
- On compare les caractères un par un.
- Dès qu’une différence apparaît, on décale le motif d’une seule position vers la droite et on recommence.
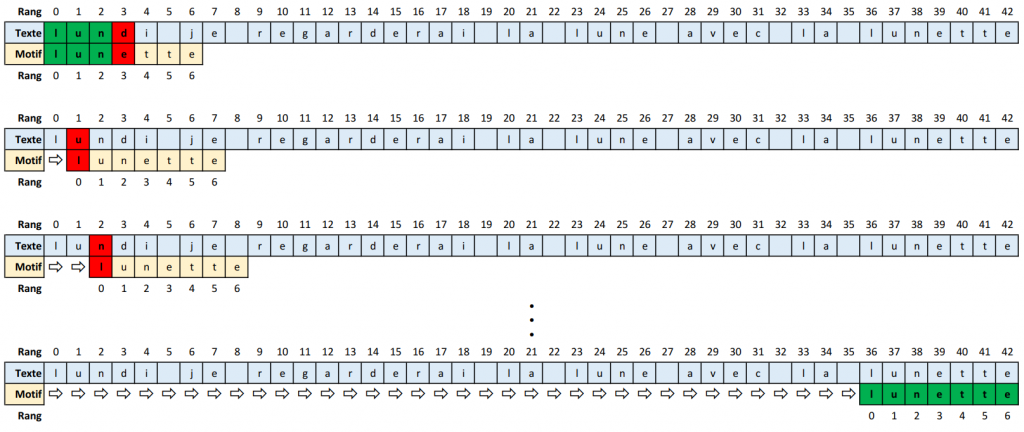
Limites :
Cet algorithme est peu efficace. Dans le pire des cas, si le texte et le motif sont très longs et répétitifs, le nombre de comparaisons devient colossal.
def occurrence(m, t, i):
"""indique s’il y a une occurrence de la chaîne m dans la chaîne t à la position i"""
# contrôler la possibilité qu'avec un i donné il puisse avoir une occurrence. On renvoie faux si ça n'est pas possible.
# en cas de faisabilité , on teste effectivement l'occurence et on renvoie vrai ou faux suivant ce que l'on obtient.
def recherche(m, t):
"""affiche toutes les occurrences de m dans t"""
# on fait une boucle avec un range pas débile et en cas d'occurence on fera un affichage pour communisuqer le rang où ça se passe.
correction à la fin de la page.
3. L’algorithme de Boyer-Moore-Horspool
L’algorithme de Boyer et Moore est un algorithme de recherche textuelle très efficace developpé en 1977. Robert Stephen Boyer et J Strother Moore travaillaient alors à l’université d’Austin au Texas en tant qu’informaticiens.
En 1980, Nigel Horspool a conçu une variante simplifiée de l’algorithme de Boyer-Moore.
C’est cette version qu’on va étudier dans ce paragraphe.
 |  |  |
| Robert Stephen Boyer | J Stroter Moore | Nigel Horspool |
L’algorithme de Boyer-Moore (souvent étudié en NSI via sa version simplifiée, l’algorithme de Boyer-Moore-Horspool) améliore considérablement les performances grâce à deux idées géniales :
- Sens de lecture : On compare les caractères du motif en partant de la droite (la fin du motif) vers la gauche.
- Sauts stratégiques : Au lieu de décaler de 1, on effectue un prétraitement du motif pour savoir de combien de cases on peut « sauter » en cas d’erreur.
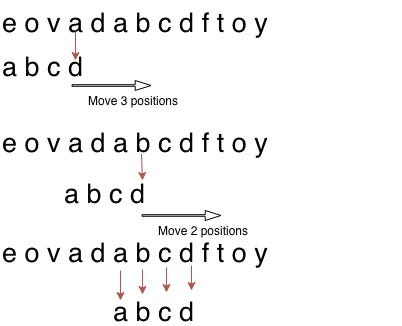
Exemple de fonctionnement :
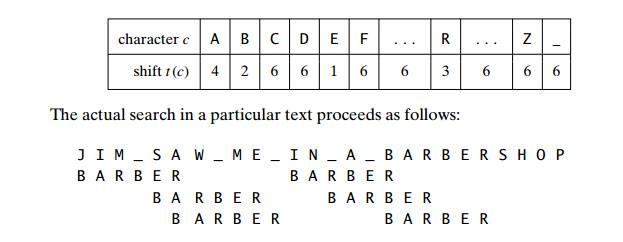
Soit le texte ADN suivant : JIM SAW ME IN THE BARBERSHOP et le motif : BARBERSHOP.
- Alignement initial : On compare la dernière lettre du motif (
T) avec la lettre correspondante du texte. - Saut de caractère : Si la lettre du texte n’existe pas du tout dans le motif, on peut décaler le motif de toute sa longueur !
- Alignement partiel : Si la lettre du texte existe dans le motif, on décale pour faire correspondre la dernière occurrence de cette lettre dans le motif.
4. Mise en pratique : Analyse d’ADN
En bioinformatique, on cherche souvent des séquences spécifiques dans l’ADN (composé des bases A, T, G, C).
À faire vous-même 1
Appliquez manuellement l’algorithme de Boyer-Moore pour trouver le motif ACCTTCG dans la séquence suivante : CAATGTCTGCACCAAGACGCCGGCAGGTGCAGACCTTCGTTATAGGCGATGATTTCGAACCTACTAGTGGGTCTCTTAGGCCGAG
À faire vous-même 2 : Implémentation Python
Voici une implémentation de l’algorithme utilisant la table des sauts (prétraitement du motif). Complétez le code en utilisant les indications :
NO_CAR = 256 # Taille du jeu de caractères ASCII
def recherche_boyer_moore(txt, motif):
m = len(motif)
n = len(txt)
# Prétraitement : on stocke la dernière position de chaque caractère du motif
# on crée une table de décallage : une liste tab_car qui à chaque caractère repéré par code ascii (avec la fonction ord()) on va associer un décalage
decalage = 0 # correspond à l'indice du placement de la première lettre du motif dans le texte
res = [] # indique où trouver les différentes occurence du motif dans le texte
while(decalage <= ?????):
j = ????? # On commence par la fin du motif, j est l'indice de la lettre
# du motif en cours de contrôle elle variera entre m-1 et 0
# On remonte vers la gauche tant que les caractères correspondent
# tant qu'avec j on est encore dans le mot et qu'il y a correspondance
#entre texte et motif on recule d'un
while j >= 0 and motif[j] == ?????:
j = j - 1
#si il y n'y a pas de problème et que toutes les lettres sont validées
if j < 0:
# Motif trouvé ! on rajoute une valeur pertinente dans la liste res
res.append(decalage)
# Décalage pour trouver l'occurrence suivante
decalage += 1 #puis on décale d'une unité
else:
# Erreur de correspondance : on utilise la table de sauts
# On commence par repèrer la lettre fautive dans le texte
# et on cherche le décalage correspondant dans la table de sauts
# et on décale
?????
return res
# Test
mon_texte = "CAAGCGCACAAGACGCGGCAGACCTTCGTTATAGGCGCAAGCGCACAAGACGCGGCAGACCTTCGTTATAGGCGACCTTCG"
mon_motif = "ACCTTCG"
print(f"Motif trouvé aux indices : {recherche_boyer_moore(mon_texte, mon_motif)}")
À faire vous-même 3
- Copiez le code ci-dessus dans votre IDE (Spyder, VS Code ou EduPython).
- Testez-le avec la séquence ADN complète fournie dans l’exercice 1.
- Comparez le temps d’exécution (théorique) avec l’algorithme naïf sur de très gros fichiers (comme un chromosome complet).
à retenir : L’algorithme naïf compare de gauche à droite et décale de 1. Complexité O(n×m).
4. L’algorithme de Boyer-Moore (Bonus)
L’algorithme Boyer-Moore compare de droite à gauche et utilise un prétraitement pour effectuer des sauts. Il est beaucoup plus efficace sur des alphabets larges et de longs motifs.
super exemple d’utilisation de l’algorithme avec beaucoup d’explication au deuxième tiers de la page suivante.
def table_bm(m):
"""construit la table de décalages de Boyer-Moore :
d[j][c] est le plus grand k < j tel que m[k] == c,
s’il existe, et n’est pas défini sinon"""
d = [{} for _ in range(len(m))]
for j in range(len(m)):
for k in range(j):
d[j][m[k]] = k
return d
def decalage(d, j, c):
"""utilise la table d lorsque le caractère j est c
au lieu du caractère attendu"""
if c in d[j]:
# c apparaît en d[j][c] et on décale de la différence
return j - d[j][c]
else:
# c n’apparaît pas du tout dans m[0..j-1]
return j + 1
def recherche(m, t):
"""affiche toutes les occurrences de m dans t
avec l’algorithme de Boyer-Moore"""
d = table_bm(m)
i = 0
while i <= len(t) - len(m):
k = 0
for j in range(len(m) - 1, -1, -1):
if t[i + j] != m[j]:
k = decalage(d, j, t[i + j])
break
if k == 0:
print("occurrence à la position", i)
k = 1
i += k
Exercices d’application
Exercice 1 : Analyse de l’algorithme Naïf
En utilisant l’algorithme naïf, déterminez le nombre de comparaisons de caractères effectuées lors de la recherche du motif "chercher" dans le texte "chercher, rechercher et chercher encore". Note : On compte chaque comparaison, même celles qui échouent dès le premier caractère.
Exercice 2 : Première occurrence
En vous inspirant du fonctionnement de l’algorithme naïf, écrivez en Python une fonction premiere_occurrence(m, t) qui renvoie l’indice de la première occurrence du motif m dans le texte t. La fonction devra renvoyer None si le motif n’est pas présent.
Exercice 3 : Table de décalages (Boyer-Moore)
Construisez manuellement la table de décalages utilisée par l’algorithme de Boyer-Moore pour le motif suivant : "banane". Rappel : Pour chaque position j du motif, on cherche la position de la dernière occurrence du caractère lu dans le texte au sein de la partie gauche du motif.
Exercice 4 : Table de décalages avancée
Construisez manuellement la table de décalages de l’algorithme de Boyer-Moore pour le motif "chercher".
Exercice 5 : Déroulé complet et comparaison
En utilisant la table de décalages obtenue à l’exercice précédent, déroulez manuellement l’exécution de l’algorithme de Boyer-Moore pour la recherche du motif "chercher" dans le texte "chercher, rechercher et chercher encore".
- Listez les valeurs successives de la variable d’indice
i. - Indiquez le nombre total de comparaisons effectuées.
- Comparez ce résultat avec celui de l’exercice 1. Quel algorithme est le plus efficace ici ?
Corrections des exercices
Correction Exercice 1
Le motif "chercher" fait 8 caractères. Le texte fait 38 caractères.
- À la position 0 : 8 comparaisons (succès).
- À la position 1 (l’espace) : 1 comparaison (échec).
- À la position 10 (début de « rechercher ») : 1 comparaison (‘r’ vs ‘c’).
- À la position 12 (le ‘c’ de « rechercher ») : 8 comparaisons (succès).
- En suivant ce processus, on compte toutes les tentatives de décalage de 1 en 1. Total : 54 comparaisons.
Correction Exercice 2
def premiere_occurrence(m, t):
n = len(t)
len_m = len(m)
for i in range(n - len_m + 1):
match = True
for j in range(len_m):
if t[i + j] != m[j]:
match = False
break
if match:
return i
return None
Correction Exercice 3 (Motif « banane »)
On liste pour chaque index j le dictionnaire des caractères rencontrés précédemment :
- j=0 :
{} - j=1 (‘a’) :
{'b': 0} - j=2 (‘n’) :
{'b': 0, 'a': 1} - j=3 (‘a’) :
{'b': 0, 'a': 1, 'n': 2} - j=4 (‘n’) :
{'b': 0, 'a': 3, 'n': 2}(le ‘a’ en 3 écrase le ‘a’ en 1) - j=5 (‘e’) :
{'b': 0, 'a': 3, 'n': 4}
Correction Exercice 4 (Motif « chercher »)
- j=0 :
{} - j=1 (‘h’) :
{'c': 0} - j=2 (‘e’) :
{'c': 0, 'h': 1} - j=3 (‘r’) :
{'c': 0, 'h': 1, 'e': 2} - j=4 (‘c’) :
{'c': 0, 'h': 1, 'e': 2, 'r': 3} - j=5 (‘h’) :
{'c': 4, 'h': 1, 'e': 2, 'r': 3} - j=6 (‘e’) :
{'c': 4, 'h': 5, 'e': 2, 'r': 3} - j=7 (‘r’) :
{'c': 4, 'h': 5, 'e': 6, 'r': 3}
Correction Exercice 5
- Valeurs de i :
- i=0 (Trouvé, on décale de 1 par défaut).
- i=1 (Espace ‘ ‘, pas dans le motif : décalage j+1, ici 7+1=8).
- i=9 (‘r’ vs ‘r’ OK, ‘e’ vs ‘e’ OK… jusqu’au ‘c’ de « rechercher »).
- i=12 (Trouvé).
- … et ainsi de suite.
- Nombre de comparaisons : Environ 22 comparaisons.
- Comparaison : Boyer-Moore est environ 2,5 fois plus efficace que l’algorithme naïf (54 vs 22 comparaisons) sur cet exemple grâce aux sauts de plusieurs caractères.
implémentations des algorithmes à connaitre :
version naïve
def occurrence(m, t, i):
"""indique s’il y a une occurrence de la chaîne m dans la chaîne t à la position i"""
if i < 0 or i > len(t) - len(m):
return False
for j in range(len(m)):
if t[i + j] != m[j]:
return False
return True
def recherche(m, t):
"""affiche toutes les occurrences de m dans t"""
for i in range(0, len(t) - len(m) + 1):
if occurrence(m, t, i):
print("occurrence à la position", i)
bayer-Moor-Horspool (version extérieure, avec une table de décalage un peu différente)
NO_CAR = 256 # Taille du jeu de caractères ASCII
def recherche_boyer_moore(txt, motif):
m = len(motif)
n = len(txt)
# Prétraitement : on stocke la dernière position de chaque caractère du motif
tab_car = [-1] * NO_CAR
for i in range(m):
tab_car[ord(motif[i])] = i
decalage = 0
res = []
while(decalage <= n - m):
j = m - 1 # On commence par la fin du motif
# On remonte vers la gauche tant que les caractères correspondent
while j >= 0 and motif[j] == txt[decalage + j]:
j = j - 1
if j < 0:
# Motif trouvé !
res.append(decalage)
# Décalage pour trouver l'occurrence suivante
if decalage + m < n:
decalage += m - tab_car[ord(txt[decalage + m])]
else:
decalage += 1
else:
# Erreur de correspondance : on utilise la table de sauts
# On décale au maximum entre 1 et la règle du mauvais caractère
decalage += max(1, j - tab_car[ord(txt[decalage + j])])
return res
# Test
mon_texte = "CAAGCGCACAAGACGCGGCAGACCTTCGTTATAGGCG"
mon_motif = "ACCTTCG"
print(f"Motif trouvé aux indices : {recherche_boyer_moore(mon_texte, mon_motif)}")
Horspool Version Kergot
NO_CAR = 256 # Taille du jeu de caractères ASCII
def recherche_boyer_moore(txt, motif):
m = len(motif)
n = len(txt)
# Prétraitement : on stocke la dernière position de chaque caractère du motif
# on crée une table de décallage : une liste tab_car qui à chaque caractère repéré par code ascii (avec la fonction ord()) on va associer un décalage
tab_car = [m] * NO_CAR
for i in range(m-1):
tab_car[ord(motif[i])] = m-1-i
decalage = 0 # correspond à l'indice du placement de la première lettre du motif dans le texte
res = [] # indique où trouver les différentes occurence du motif dans le texte
while(decalage <= n - m):
j = m - 1 # On commence par la fin du motif, j est l'indice de la lettre
# du motif en cours de contrôle elle variera entre m-1 et 0
# On remonte vers la gauche tant que les caractères correspondent
# tant qu'avec j on est encore dans le mot et qu'il y a correspondance
#entre texte et motif on recule d'un
while j >= 0 and motif[j] == txt[decalage + j]:
j = j - 1
#si il y n'y a pas de problème et que toutes les lettres sont validées
if j < 0:
# Motif trouvé ! on rajoute une valeur pertinente dans la liste res
res.append(decalage)
# Décalage pour trouver l'occurrence suivante
decalage += 1 #puis on décale d'une unité
else:
# Erreur de correspondance : on utilise la table de sauts
# On commence par repèrer la lettre fautive dans le texte
# et on cherche le décalage correspondant dans la table de sauts
# et on décale
decalage += tab_car[ord(txt[decalage + j])]
return res
# Test
mon_texte = "CAAGCGCACAAGACGCGGCAGACCTTCGTTATAGGCGCAAGCGCACAAGACGCGGCAGACCTTCGTTATAGGCGACCTTCG"
mon_motif = "ACCTTCG"
print(f"Motif trouvé aux indices : {recherche_boyer_moore(mon_texte, mon_motif)}")