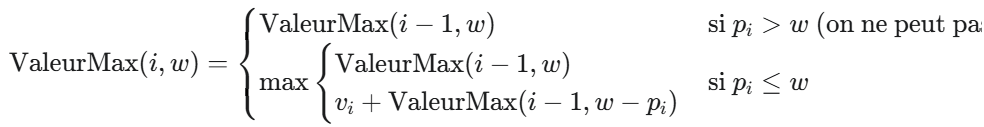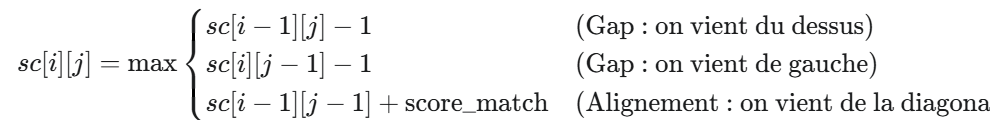activité
Corrigé de l’Exercice 1 : Le Problème de la Coupe de Barres d’Acier (Rod Cutting)
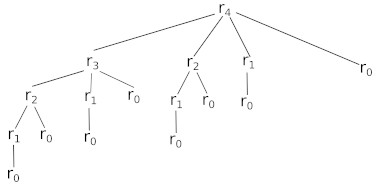
Ce problème vise à trouver le revenu maximal rn qu’on peut obtenir en coupant une barre de longueur n.
| Longueur i (m) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Prix pi (€) | 1 | 5 | 8 | 9 | 10 | 17 | 17 | 20 | 24 | 30 |
Exporter vers Sheets
Partie I : Analyse et Récursivité Naïve
1. Exploration des possibilités pour n=4 :
| Découpe | Longueurs | Revenu |
| Vente entière | 4 | 9€ |
| Deux morceaux | 2+2 | 5+5=10€ |
| Deux morceaux | 1+3 | 1+8=9€ |
| Deux morceaux | 3+1 | 8+1=9€ |
| Trois morceaux | 1+1+2 | 1+1+5=7€ |
| Trois morceaux | 1+2+1 | 1+5+1=7€ |
| Trois morceaux | 2+1+1 | 5+1+1=7€ |
| Quatre morceaux | 1+1+1+1 | 1+1+1+1=4€ |
Exporter vers Sheets
Le revenu maximum possible pour une barre de 4 m est de r4=10€ (obtenu par la découpe 2+2).
2. Retrouver r4 avec la Relation de Récurrence :
La relation est rn=max(pn,r1+rn−1,r2+rn−2,…,rn−1+r1). On utilise la forme simplifiée : rn=max1≤i≤n(pi+rn−i), avec r0=0.
Pour n=4, on a :
r4=max(p1+r3, p2+r2, p3+r1, p4+r0)r4=max(1+8, 5+5, 8+1, 9+0)r4=max(9, 10, 9, 9)=10
3. Compléter la Fonction Récursive (Naïve) :
La fonction implémente la relation rn=max1≤i≤n(pi+rn−i). Le terme manquant dans la boucle est la valeur récursive du reste de la barre : revenu_barre(n-i).
Python
def revenu_barre(n):
prix = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] # Indice 0 inutilisé
if n == 0:
return 0 # Cas de base: revenu pour une barre de longueur 0 est 0
r = float('-inf')
for i in range(1, n + 1):
# r = max(r, prix[longueur_du_premier_morceau] + revenu_max_du_reste)
r = max(r, prix[i] + revenu_barre(n - i))
return r
4. Application des Tarifs Initiaux :
En exécutant la fonction revenu_barre(n) avec les tarifs initiaux :
- r5=13€ (Découpe : 2+3 ou 3+2)
- r6=17€ (Découpe : 6 entier)
- r7=18€ (Découpe : 1+6 ou 6+1)
- r8=22€ (Découpe : 2+6 ou 6+2)
- r9=25€ (Découpe : 1+8 ou 8+1)
- r10=30€ (Découpe : 10 entier)
5. Changement de Tarifs :
Le tableau prix doit être mis à jour. Nouvelle liste des prix : prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
En réexécutant la fonction avec les nouveaux prix :
- r5=15€ (Découpe : 2+3)
- r6=19€ (Découpe : 6 entier)
- r7=21€ (Découpe : 1+6 ou 6+1)
- r8=25€ (Découpe : 2+6 ou 6+2)
- r9=28€ (Découpe : 3+6 ou 6+3)
- r10=31€ (Découpe : 2+8 ou 8+2)
Partie II : Optimisation par Programmation Dynamique
6. Approche Descendante (Mémorisation) :
On utilise un tableau mem pour stocker les résultats et éviter de recalculer rk.
Python
def revenu_barre_dyn_desc(n):
prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
mem = [-1] * (n + 1) # -1 indique que le revenu n'a pas encore été calculé
def r_mem(k):
if k == 0:
return 0
# 1. Vérification : Si déjà calculé, retourner le résultat mémorisé
if mem[k] != -1:
return mem[k]
# 2. Calcul : Sinon, calculer le revenu maximal
r_max = float('-inf')
for i in range(1, k + 1):
# Utiliser r_mem(k - i) pour l'appel récursif (mémorisé)
r_max = max(r_max, prix[i] + r_mem(k - i))
# 3. Mémorisation : Stocker le résultat avant de le retourner
mem[k] = r_max
return r_max
return r_mem(n)
7. Approche Ascendante (Itérative) :
On construit le tableau des revenus maximaux tab de bas en haut, de r1 à rn.
Python
def revenu_barre_dyn_asc(n):
prix = [0, 1, 6, 9, 11, 12, 19, 20, 23, 24, 26]
tab = [0] * (n + 1) # tab[i] stockera le revenu maximal ri
# tab[0] est déjà à 0 (r0 = 0)
# On itère de la longueur m=1 à m=n
for m in range(1, n + 1):
r_max = float('-inf')
# On calcule le revenu maximal pour la longueur m
for i in range(1, m + 1):
# Calcul r_max = max(pi + r_m-i)
# tab[m-i] contient le revenu r_m-i déjà calculé
r_max = max(r_max, prix[i] + tab[m - i])
tab[m] = r_max
return tab[n]
Corrigé de l’Exercice 2 : Score Maximal dans une Pyramide de Nombres
Pyramides utilisées :
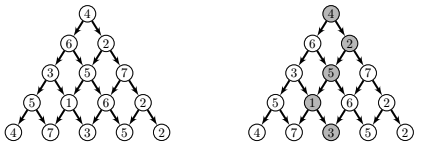
ex1 = [[4],[6,2],[3,5,7],[5,1,6,2],[4,7,3,5,2]]ex2 = [[3],[1,2],[4,5,9],[3,6,2,1]]
Partie I : Représentation et Fonctions de Base
1. Dessiner la pyramide ex2 :
[3]
[1, 2]
[4, 5, 9]
[3, 6, 2, 1]
2. Dessiner le chemin ch2 = [0,1,2,2] dans ex2 :
| Niveau | Indice | Nombre |
| 0 | 0 | 3 |
| 1 | 1 | 2 |
| 2 | 2 | 9 |
| 3 | 2 | 2 |
Exporter vers Sheets
Le chemin est : 3→2→9→2.
3. Calculer le score de ch2 :
3+2+9+2=16
4. Fonction est_chemin(ch, p) :
Python
def est_chemin(ch, p):
# Règle 1: La longueur doit correspondre au nombre de niveaux
if len(ch) != len(p):
return False
# Règle 2: Doit commencer par 0
if ch[0] != 0:
return False
# Règle 3: Vérification du déplacement
for i in range(len(ch) - 1):
a = ch[i]
b = ch[i+1]
# Le nouvel indice (b) doit être a ou a + 1
if not (b == a or b == a + 1):
return False
# Si toutes les règles sont respectées
return True
# Tests :
# est_chemin([0,1,2,2], ex2) -> True
# est_chemin([0, 0, 0, 2], ex2) -> False (problème à l'étape 3, 0 -> 2)
5. Fonction score(ch, p) :
Python
def score(ch, p):
s = 0
# Parcourt chaque niveau (i) de la pyramide et l'indice (j) du chemin
for i in range(len(p)):
j = ch[i]
s += p[i][j]
return s
# Test :
# score([0,1,1,1,2], ex1) -> 4 + 2 + 5 + 1 + 3 = 15
Partie II : Programmation Dynamique pour l’Optimisation
6. Fonction calcule_score_max(p) (Récursive Naïve) :
On utilise la relation récursive score_max(i,j)=p[i][j]+max(score_max(i+1,j),score_max(i+1,j+1)).
Python
def calcule_score_max(p, i=0, j=0):
# Cas de base (dernier niveau)
if i == len(p) - 1:
return p[i][j]
# Cas récursif: valeur du niveau courant + max des scores des deux sous-pyramides
gauche = calcule_score_max(p, i + 1, j)
droite = calcule_score_max(p, i + 1, j + 1)
return p[i][j] + max(gauche, droite)
# Le score maximal est obtenu par calcule_score_max(ex1)
7. Fonction pyramide_nulle(n) :
La pyramide doit avoir n niveaux, avec i+1 éléments au niveau i.
Python
def pyramide_nulle(n):
pyramide = []
for i in range(n):
# Chaque niveau i a une taille de i + 1
pyramide.append([0] * (i + 1))
return pyramide
# Exemple: pyramide_nulle(4) -> [[0],[0,0],[0,0,0],[0,0,0,0]]
8. Fonction prog_dyn(p) (Ascendante) :
On remplit la pyramide des scores s de bas en haut (du dernier niveau au sommet).
Python
def prog_dyn(p):
n = len(p)
if n == 0:
return 0
# Création de la pyramide des scores maximaux (s)
# L'approche ascendante utilise souvent un tableau de la taille des données d'entrée.
# Pour simplifier, on peut initialiser s avec la structure de p (ou une copie)
s = [list(niveau) for niveau in p]
# On commence par l'avant-dernier niveau et on remonte jusqu'au sommet (niveau 0)
for i in range(n - 2, -1, -1):
# Pour chaque élément (j) du niveau i
for j in range(len(s[i])):
# Application de la relation de récurrence (score_max)
# p[i][j] + max(score_max(i+1, j), score_max(i+1, j+1))
# Les valeurs score_max(i+1, ...) sont déjà calculées au niveau i+1 de s.
max_suivants = max(s[i+1][j], s[i+1][j+1])
# Mise à jour du score maximal pour l'élément (i, j)
s[i][j] = p[i][j] + max_suivants
# Le score maximal pour la pyramide entière est au sommet
return s[0][0]
# Test : prog_dyn(ex1) -> 4 + max(6, 2) + ... -> 23
9. Ordre de grandeur du coût de prog_dyn(p) :
La fonction prog_dyn(p) effectue deux boucles imbriquées :
- La boucle extérieure parcourt les niveaux, de i=n−2 à 0 (soit ≈n niveaux).
- La boucle intérieure parcourt les éléments j à chaque niveau. Au niveau i, il y a i+1 éléments.
Le nombre total d’opérations est proportionnel à la somme du nombre d’éléments dans la pyramide :
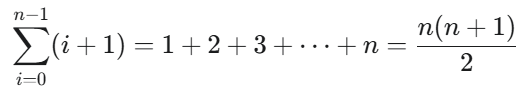
Le coût est donc dominé par n2. L’ordre de grandeur du coût est O(n2) (où n est le nombre de niveaux), ce qui est bien plus performant que l’approche récursive naïve en O(2n).
exercices
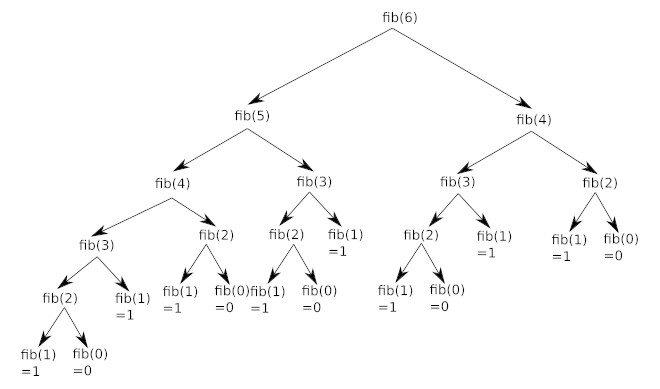
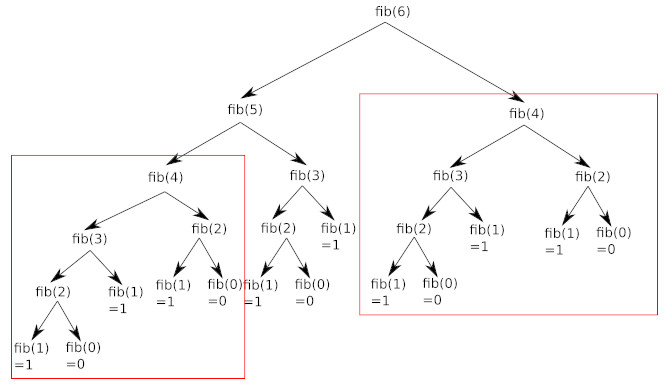
Exercice 1 Appels Redondants
Analyse des Appels Récursifs : L’exécution de rendu_monnaie([1, 2], 3) génère la séquence d’appels suivante :
rendu_monnaie(..., 3)- Appelle
rendu_monnaie(..., 3 - 1 = 2) - Appelle
rendu_monnaie(..., 3 - 2 = 1)
- Appelle
rendu_monnaie(..., 2)- Appelle
rendu_monnaie(..., 2 - 1 = 1) - Appelle
rendu_monnaie(..., 2 - 2 = 0)
- Appelle
rendu_monnaie(..., 1)- Appelle
rendu_monnaie(..., 1 - 1 = 0)
- Appelle
rendu_monnaie(..., 0)→ Retourne 0rendu_monnaie(..., 1)(Appelé depuis s=2)- Appelle
rendu_monnaie(..., 1 - 1 = 0)
- Appelle
rendu_monnaie(..., 0)→ Retourne 0rendu_monnaie(..., 0)→ Retourne 0
Conclusion sur la Redondance : Sur les 7 appels totaux (en comptant le premier), on constate que :
- Le sous-problème pour la somme s=1 a été calculé 2 fois.
- Le sous-problème pour la somme s=0 a été calculé 3 fois.
Ceci illustre le principe des sous-problèmes qui se chevauchent, caractéristique des problèmes résolus par Programmation Dynamique.
.
Corrigé 2 : Calcul du Tableau nb
Système de pièces : P={1,6,10}. Somme finale : S=12. Le tableau nb a une taille S+1=13 (indices 0 à 12). nb[0]=0.
| n | Initialisation | p=1 (1 + nb[n−1]) | p=6 (1 + nb[n−6]) | p=10 (1 + nb[n−10]) | nb[n] Final |
| 0 | 0 | – | – | – | 0 |
| 1 | 1 | min(1,1+0)=1 | – | – | 1 |
| 2 | 2 | min(2,1+1)=2 | – | – | 2 |
| 3 | 3 | min(3,1+2)=3 | – | – | 3 |
| 4 | 4 | min(4,1+3)=4 | – | – | 4 |
| 5 | 5 | min(5,1+4)=5 | – | – | 5 |
| 6 | 6 | min(6,1+5)=6 | min(6,1+0)=1 | – | 1 |
| 7 | 7 | min(7,1+1)=2 | min(2,1+1)=2 | – | 2 |
| 8 | 8 | min(8,1+2)=3 | min(3,1+2)=3 | – | 3 |
| 9 | 9 | min(9,1+3)=4 | min(4,1+3)=4 | – | 4 |
| 10 | 10 | min(10,1+4)=5 | min(5,1+4)=5 | min(5,1+0)=1 | 1 |
| 11 | 11 | min(11,1+1)=2 | min(2,1+5)=2 | min(2,1+1)=2 | 2 |
| 12 | 12 | min(12,1+2)=3 | min(3,1+6)=3 | min(3,1+2)=2 | 2 |
Exporter vers Sheets
Tableau Final nb :
[0,1,2,3,4,5,1,2,3,4,1,2,2]
Le résultat final est nb[12]=2 (par exemple, 6+6 ou 10+2).
.
Corrigé 3 : Code Python avec Solution
Pour suivre la solution optimale, nous ajoutons un deuxième tableau, sol, qui mémorise la liste des pièces pour chaque somme n. Lorsque nous trouvons un meilleur score (1 + nb[n - p] < nb[n]), nous mettons à jour la solution en copiant la solution du sous-problème (sol[n - p]) et en lui ajoutant la pièce p qui a permis cette amélioration.
Python
def rendu_monnaie_solution(pieces, s):
"""
Renvoie la liste minimale de pièces pour faire la somme s
avec le système 'pieces' (Programmation Dynamique).
"""
# Initialisation au pire cas (n pièces de 1)
nb = [n for n in range(s + 1)] # Nombre minimal de pièces
sol = [[1] * n for n in range(s + 1)] # Liste des pièces utilisées pour chaque somme
sol[0] = []
for n in range(1, s + 1):
for p in pieces:
if p <= n:
# Si prendre la pièce p mène à un meilleur nombre total de pièces
if 1 + nb[n - p] < nb[n]:
nb[n] = 1 + nb[n - p]
# Mise à jour de la solution :
# Prendre la solution optimale pour le reste (n-p) et ajouter la pièce p
sol[n] = sol[n - p].copy()
sol[n].append(p)
# Retourne la solution optimale pour la somme s
return sol[s]
Corrigé 4 : Code Python pour Fibonacci
La solution utilise un tableau f pour stocker toutes les valeurs F0,F1,…,Fn et les calculer de manière itérative, de bas en haut.
Python
def fibonacci(n):
if n < 0:
raise ValueError("n doit être positif")
if n == 0:
return 0
# Création du tableau de mémorisation F[0] à F[n]
f = [0] * (n + 1)
# Initialisation des cas de base
# f[0] = 0 (déjà fait par l'initialisation)
f[1] = 1
# Calcul itératif de F[2] jusqu'à F[n]
for i in range(2, n + 1):
# f[i] = f[i-2] + f[i-1] (Approche ascendante)
f[i] = f[i - 2] + f[i - 1]
return f[n]
Corrigé 5 : Tableau des Scores d’Alignement
Mots : s1= »CHAT » (n1=4) et s2= »CAT » (n2=3).
| sc | − | C | A | T |
| − | 0 | -1 | -2 | -3 |
| C | -1 | 1 | 0 | -1 |
| H | -2 | 0 | 0 | 0 |
| A | -3 | -1 | 1 | 0 |
| T | -4 | -2 | 0 | 2 |
Calculs clés :
- sc[1][1] (C vs C) : max(−1+sc[0][1],−1+sc[1][0],1+sc[0][0])max(−1−1,−1−1,1+0)=max(−2,−2,1)=1
- sc[2][2] (H vs A) : max(−1+sc[1][2],−1+sc[2][1],−1+sc[1][1])max(−1+0,−1+0,−1+1)=max(−1,−1,0)=0
- sc[4][3] (T vs T) : max(−1+sc[3][3],−1+sc[4][2],1+sc[3][2])max(−1+0,−1+0,1+1)=max(−1,−1,2)=2
Le score maximal d’alignement (valeur dans la dernière case) est 2. (Un alignement optimal est : CH-AT contre C-AT, score 1−1+1+1=2).
Corrigé 6 : Alignement AAAAAAAAAA vs BBBBBBBBBB
Score Maximal : Puisque tous les caractères sont différents, il n’y a aucun match possible. Chaque paire alignée (A,B) est un mismatch avec un score de −1. Un alignement optimal sera l’un des deux suivants :
- 10 Mismatchs : Score 10×(−1)=−10.
- Gaps : L’alignement sera au maximum 10×(−1)=−10.
Le score maximal est −10.
Forme du Tableau (sc) : Le tableau sc a une taille 11×11.
| sc | − | B | B | … | B |
| − | 0 | -1 | -2 | … | -10 |
| A | -1 | -1 | -2 | … | -10 |
| A | -2 | -2 | -2 | … | -10 |
| A | -3 | -3 | -3 | … | -10 |
| … | … | … | … | … | … |
| A | -10 | -10 | -10 | … | -10 |
Explication de la Forme :
- Bords (Ligne 0 et Colonne 0) : Remplis par les scores de gap : −i ou −j.
- Intérieur : Pour chaque case sc[i][j], la valeur est max(−1+sc[i−1][j],−1+sc[i][j−1],−1+sc[i−1][j−1]).
- La meilleure option est toujours de prolonger l’alignement existant ou de le commencer.
- La valeur sc[i][j] est max(sc[i−1][j],sc[i][j−1],sc[i−1][j−1])−1.
- La structure triangulaire de −i sur la diagonale supérieure puis −j sur la diagonale inférieure n’est pas correcte. En réalité, le score sera simplement −max(i,j), car on peut toujours aligner la partie la plus courte avec des gaps et terminer avec des mismatchs. Dans ce cas particulier, sc[i][j]=−max(i,j).
(La correction fournie dans l’énoncé original semble contenir une erreur dans sa description de la structure générale du tableau pour ce cas).
Corrigé 7 : Fonction d’Affichage Formattée
La fonction utilise la méthode de formatage {:>3} pour assurer que chaque élément (caractère ou score) occupe exactement 3 espaces, aligné à droite.
Python
def affiche(s1, s2, sc):
"""Affiche la table des scores d'alignement de manière formattée."""
# 1. Affichage de l'en-tête de colonne (s2)
print(" ", end="") # Espace pour l'angle supérieur gauche
for c in s2:
print('{:>3}'.format(c), end="")
print() # Retour à la ligne pour le début du tableau
# 2. Affichage des lignes (s1 et scores)
for i in range(len(sc)): # i va de 0 à len(s1)
# Affichage du caractère de début de ligne (s1[i-1] ou espace/tirets pour la ligne 0)
if i > 0:
print('{:>3}'.format(s1[i - 1]), end="")
else:
print(" ", end="") # Espace pour la première ligne (index 0)
# Affichage des scores de la ligne
for v in sc[i]:
print('{:>3}'.format(v), end="")
print() # Retour à la ligne pour la ligne suivante
# Exemple d'utilisation (avec les données de l'exercice 5) :
# s1 = "CHAT", s2 = "CAT", sc = [[0,-1,-2,-3],[-1,1,0,-1],[-2,0,0,0],[-3,-1,1,0],[-4,-2,0,2]]
# affiche(s1, s2, sc)
# C A T
# 0 -1 -2 -3
# C -1 1 0 -1
# H -2 0 0 0
# A -3 -1 1 0
# T -4 -2 0 2
Corrigé 8 : Reconstruction de la Solution
Nous introduisons un deuxième tableau, sol, qui, pour chaque paire d’indices (i,j), stocke la meilleure séquence d’alignement trouvée jusqu’à cet état (s1[0:i],s2[0:j]).
Python
def aligne_solution(s1, s2):
n1, n2 = len(s1), len(s2)
sc = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# sol[i][j] stockera le couple (align_s1, align_s2) optimal jusqu'à s1[i-1], s2[j-1]
sol = [[("", "")] * (n2 + 1) for _ in range(n1 + 1)]
# Initialisation des bords (Gaps)
for i in range(1, n1 + 1):
sc[i][0] = -i
sol[i][0] = (s1[0:i], "-" * i) # Alignement de s1[0:i] avec des gaps
for j in range(1, n2 + 1):
sc[0][j] = -j
sol[0][j] = ("-" * j, s2[0:j]) # Alignement de s2[0:j] avec des gaps
# Reste du tableau
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
# Options possibles et leurs scores
score_gap_s1 = -1 + sc[i - 1][j] # Gap dans s2 (vertical)
score_gap_s2 = -1 + sc[i][j - 1] # Gap dans s1 (horizontal)
# Match ou Mismatch
sim_score = 1 if s1[i - 1] == s2[j - 1] else -1
score_diag = sim_score + sc[i - 1][j - 1] # Diagonale
# Détermination du score maximal et de la solution correspondante
# 1. Initialisation avec le meilleur score connu (souvent un gap)
s_max = score_gap_s1
(x, y) = sol[i - 1][j]
sol[i][j] = (x + s1[i - 1], y + "-") # Aligne s1[i-1] avec un gap
# 2. Test du Gap dans s1
if score_gap_s2 > s_max:
s_max = score_gap_s2
(x, y) = sol[i][j - 1]
sol[i][j] = (x + "-", y + s2[j - 1]) # Aligne s2[j-1] avec un gap
# 3. Test de la Diagonale (Match ou Mismatch)
if score_diag > s_max:
s_max = score_diag
(x, y) = sol[i - 1][j - 1]
sol[i][j] = (x + s1[i - 1], y + s2[j - 1]) # Aligne les deux caractères
sc[i][j] = s_max
# Retourne le score et le couple de chaînes alignées
return sc[n1][n2], sol[n1][n2]
Corrigé 9 : Adaptation du Programme pour la Biologie
Représentation de la Matrice de Similarités : Le format le plus pratique est un dictionnaire imbriqué (un dictionnaire de dictionnaires), permettant un accès facile O(1) par caractère :
Python
sim = {
'A': {'A': 10, 'G': -1, 'C': -3, 'T': -4},
'G': {'A': -1, 'G': 7, 'C': -5, 'T': -3},
'C': {'A': -3, 'G': -5, 'C': 9, 'T': 0},
'T': {'A': -4, 'G': -3, 'C': 0, 'T': 8}
}
gap = -5 # Coût du gap
Modification du Programme 48 : On remplace le score fixe de −1 pour les gaps et le score conditionnel de ±1 pour la diagonale par les valeurs de gap et de la matrice sim.
Python
def aligne_custom(s1, s2, sim, gap):
n1, n2 = len(s1), len(s2)
sc = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# Initialisation des bords avec le coût de gap
for i in range(1, n1 + 1):
sc[i][0] = i * gap # -1 est remplacé par gap
for j in range(1, n2 + 1):
sc[0][j] = j * gap # -1 est remplacé par gap
# Le reste
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
# 1. Score de Gap dans s2 (déplacement vertical)
score_gap_s2 = gap + sc[i - 1][j]
# 2. Score de Gap dans s1 (déplacement horizontal)
score_gap_s1 = gap + sc[i][j - 1]
# 3. Score d'alignement (déplacement diagonal)
# Utilisation de la matrice sim
score_sim = sim[s1[i - 1]][s2[j - 1]] + sc[i - 1][j - 1]
# Score maximal parmi les trois options
sc[i][j] = max(score_gap_s1, score_gap_s2, score_sim)
return sc[n1][n2]
Corrigé 10 : Dénombrement sur Grille
Ce problème est résolu par la relation de récurrence : le nombre de chemins pour atteindre une case (i,j) est la somme des chemins pour atteindre la case du dessus (i−1,j) et la case de gauche (i,j−1).
chemins(i,j)=chemins(i−1,j)+chemins(i,j−1)
Cas de base :
- Le nombre de chemins pour atteindre n’importe quelle case sur la première ligne (i=0) ou la première colonne (j=0) est toujours 1.
Python
def chemins(n, m):
"""
Calcule le nombre de chemins de (0, 0) à (n, m) sur une grille,
avec déplacements uniquement à droite ou en bas.
"""
# La grille aura (n+1) lignes et (m+1) colonnes
grille = [[0] * (m + 1) for _ in range(n + 1)]
# Initialisation des bords (Cas de base: 1 chemin pour atteindre n'importe quelle case de la bordure)
for i in range(n + 1):
grille[i][0] = 1
for j in range(m + 1):
grille[0][j] = 1
# Remplissage de la grille par approche ascendante
for i in range(1, n + 1):
for j in range(1, m + 1):
# Le nombre de chemins pour (i, j) est la somme des chemins depuis le haut et la gauche
grille[i][j] = grille[i - 1][j] + grille[i][j - 1]
return grille[n][m]
# Vérification : chemins(2, 2) = 6 (Comme mentionné en introduction)